
散点图缩放所产生的偏见
IEEE引用格式:Y. Wei et al., “Evaluating perceptual bias during geometric scaling of scatterplots,” IEEE Trans. Vis. Comput. Graph., vol. 26, no. 1, pp. 321–331, 2020, doi: 10.1109/TVCG.2019.2934208.
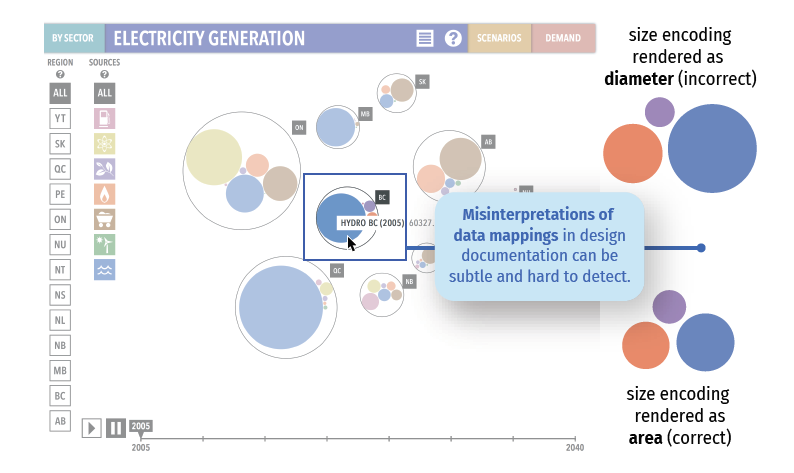
文章简介在现代数据分析场景中,散点图经常被缩放以适应不同的显示,同时在不同显式设备上共享散点图是协作数据分析交流中的一种常规操作
缩放散点图最直接的方法几何缩放(同步和比例地放大或缩小整个图以及其中的对象)。几何变化会导致视觉感知偏见,从而影响数据特征的感知一致性(数量、相关性和聚类),不利于交互式数据探索,如上图所示,在讲述者的散点图中有两个簇,然而显示在移动设备上的时候,这是无法区分的,在下图中,左右两个方框内具有相同数量的点,但是人们总会认为右边方框中的点是更多的,此外,心理学研究证明,当patch的大小增加时,patch的点被认为是稀疏的
已有的研究考虑了散点图的设计决策(点颜色,宽高比 ...

信息可视化中的认知偏见
IEEE引用格式:E. Dimara, S. Franconeri, C. Plaisant, A. Bezerianos, and P. Dragicevic, “A Task-Based Taxonomy of Cognitive Biases for Information Visualization,” IEEE Trans. Vis. Comput. Graph., vol. 26, no. 2, pp. 1413–1432, 2020, doi: 10.1109/TVCG.2018.2872577.
文章简介可视化设计师必须考虑三种限制:计算机的限制、显示器的限制和人的限制,对于人的限制来说,设计师必须考虑人类视觉的局限性以及人类推理的局限性。本文关注的是后者,强调人类判断和决策的缺陷
我们的判断和决定通常依赖于近似值、启发式和经验法则,即使我们没有意识到这些策略,这些策略的缺陷表现为认知偏差,虽然可视化工具是用来支持判断和决策的,但人们对认知偏见如何影响人们使用工具知之甚少,要理解可视化如何支持判断和决策,我们首先需要理解人类推理的局限性如何影响可视化数据分析
在信息 ...
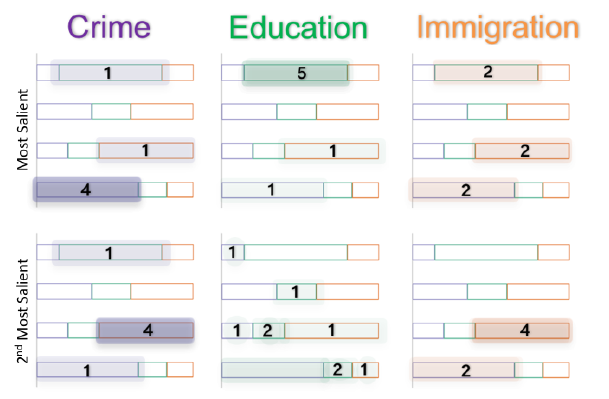
可视化中知识的诅咒
这篇是VIS的Bias & Patterns标签下的一篇文章
IEEE引用格式:C. Xiong, L. van Weelden, and S. Franconeri, “The Curse of Knowledge in Visual Data Communication,” IEEE Trans. Vis. Comput. Graph., pp. 1–1, 2019, doi: 10.1109/tvcg.2019.2917689.
文章简介在专家发表演讲时,与观众的信息处理能力相比,可视化的数据往往传递的过快过复杂而让人难以接受,而演讲人则通常忽略这一事实,这个现象称为知识的诅咒
知识的诅咒对交流有极大的影响,若人们认为信息已共享,则他们通常不会把信息传递给他人,这意味着演讲者必须准确知道观众知道什么,不知道什么,才能包含观众需要的信息
与数字和文本格式相比,数据可视化可以有效地突出显示数据中的关系和模式,但同时理解复杂的可视化就像读一个段落,不同的解读方式得到不同的结果,通过可视化数据进行交流能否成功,部分取决于预测,避免和纠正沟通失败的能力
本文的实验结果表明了,由 ...
Data Changes Everything
这是看的第一篇关于可视化方向的顶会文章(VIS2019 Best Paper),感觉跟CVPR的行文思路差别有点大,大致翻译了一下,可能会有些纰漏
引用格式:J. Walny et al., “Data Changes Everything: Challenges and Opportunities in Data Visualization Design Handoff,” IEEE Trans. Vis. Comput. Graph., vol. 26, no. 1, pp. 12–22, 2020, doi: 10.1109/TVCG.2019.2934538.
文章简介创建自定义可视化是一个具有挑战性的、多方面的问题,需要结合用于数据分析、设计和开发的技能和工具,设计人员和开发人员必须通过数据探索了解数据集及其特征,然后基于它设计数据映射、美学和交互,这些设计也需要实现和部署,通常是通过编写软件,有时,如果有足够的时间和资源,一个人可以完成所有这些活动,然而,对于具有有限时间线的更复杂的可视化项目,将这些活动分配给具有特定角色的人员是更可行的
角色的这种分布产生了在项目中从 ...
![Causal TDE Inference [因果效应]](https://forever97-picture-bed.oss-cn-hangzhou.aliyuncs.com/img/causalTDE-1.png)
Causal TDE Inference [因果效应]
Paper Download Address
Code Download Address
文章简介场景图生成(SGG)——图像中对象和其关系的视觉检测任务,似乎从未真正实现其承诺:以一种全面的视觉场景表示支持高级任务的图推理,如视觉字幕和VQA
图中展示了SOTA模型的SGG结果,可以发现在几乎所有被检测到的物体之间的视觉关系大多是琐碎的,信息量也不大,如图c,在二维关系中除了near,has和on之外,我们所知甚少,这种严重偏见的生成来自于有偏见的训练数据,即存在长尾效应,因此,要执行合理的图推理需要区分出更细粒度的关系,比如将near替换成behind/in front of,将on替换成parking on/driving on
然而,我们不应该责怪有偏见的训练,因为我们的视觉世界本身和我们描述它的方式都是有偏见的:比如人带着包的情况总归是比狗带着包的情况要更多一些的(长尾理论 long-tail theory),对于人和桌子的关系,near的标注总比eating on要简单的多的(有限理性 bounded rationality),我们更喜欢说person on bike而不 ...
![RAMEN [early fusion]](https://forever97-picture-bed.oss-cn-hangzhou.aliyuncs.com/img/RAMEN-2.png)
RAMEN [early fusion]
Paper Download Address
文章简介VQA问题要求模型理解并推理视觉-文本内容以回答端到端的关于图片的问题,正确回答这些问题需要模型具备许多能力比如:目标定位,属性检测,活动分类,场景理解,推理,计数等等,第一个VQA数据集包含了真实世界图片以及一系列问题和对应的答案,然而,许多高性能算法只是利用了偏见和表面的相关性,而没有真正理解视觉内容,后来的自然图像VQA数据集努力解决这个问题,VQAv2通过将每个问题与互补的图像和不同的答案练习起来减少了某种形式的语言偏差(bias),TDIUC分析了多种问题和罕见答案的泛化,CVQA测试了概念的组合性,VQAcpv2测试了在训练集和测试集分布不同时的性能
虽然后来的自然图像数据集已经减少了偏差,但这些数据集中的绝大多数问题并没有严格测试推理技能,所以有了合成数据集对这一方面做了一个补充,为了正确评估算法的健壮性,这些数据集的创建者认为算法应该在两个领域进行测试
然而,几乎所有近期的文章都只是在两个领域的其中之一做报告,CLEVR上表现最好的算法并没有在真实VQA数据集中测试,反之亦然,作者发现大多数方法并不能同时在两个领域取 ...
![CTI-VQA [知识蒸馏]](https://forever97-picture-bed.oss-cn-hangzhou.aliyuncs.com/img/CTIVQA-16.png)
CTI-VQA [知识蒸馏]
Paper Download Address
文章简介传统的VQA模型分为两类,一类是自由形式回答的Free-Form Opened-Ended(FFOE),另一类是多选题Multiple Choice(MC)
两种VQA任务的传统方法主要是学习图像和问题的联合表示,而对答案的处理都是”被动”的,即只将答案视为分类目标,但是一个答案与其对应的问题图像输入具有很高的相关性,因此,从这三个输入中联合而明确地提取信息将会给出一个非常有价值的联合表示,因此作者在这篇文章中提出了一种新的三线性交互模型,以学习三种输入(图片,问题,答案)之间的高水平的关联
三线性交互的主要难点是维数问题,计算量大,内存需求大,为了解决这个问题,作者提出了利用PARALIND分解将一个大张量分解为小张量,从而减少了计算量和内存的使用
FFOE VQA中的答案信息只在训练阶段提供,在测试阶段不提供,为了将三线性交互应用于FFOE VQA中,作者提出利用知识蒸馏将三线性模型转化为双线性模型,提取的双线性模型只需要对图像和问题作为输入,因此可以用于测试阶段,而对于MC VQA,则可以直接利用三线性模型,作者在TDIUC, ...

将迁移学习应用于VQA
Paper Download Address
文章简介VQA的方法依赖于大规模的图像数据集、问题和回答三元组,训练一个分类器,将图像和问题作为输入,然后生成一个答案,尽管最近取得了显著的进展,但这个框架有一个关键的局限性,即数据集中的图像、问题和回答三元组是学习视觉概念的唯一来源,这种缺陷可能会导致可扩展性的缺乏,因为标注人员可能会在质量控制有限的情况下人为地收集三元组,并且在视觉概念上多样性较弱
人类回答问题则是基于视觉概念的,视觉概念来自多个来源,比如书,图片,视频或是个人经验,但这些不一定和目标问题相关,机器也有很多可扩展的学习视觉概念的资源:图像类标签,边框和图像描述,那么能否学习没有标注的视觉概念并将其迁移到VQA系统中呢?
为了解决这个问题,作者引入了一个包含词汇表之外答案的VQA问题,如图所示
文章研究了在没有问题的情况下对视觉概念的学习,以及如何将学习到的视觉概念转化为VQA模型,文章提出的迁移学习框架有助于在词汇量不足的VQA中进行泛化
文章的主要贡献如下:
提出了一种基于任务条件视觉分类器的视觉问题回答迁移学习算法
提出了一种非监督任务发现技术,用于学习任务条件 ...
![RUBi [question-only分支]](https://forever97-picture-bed.oss-cn-hangzhou.aliyuncs.com/img/RUBi-9.png)
RUBi [question-only分支]
Paper Download Address
Code Download Address
文章简介VQA模型倾向于利用答案的出现和问题中的某些模式之间的统计规律来回答问题,虽然它们被设计来合并来自两种模态的信息,但在实践中,它们通常不考虑图像模态,当大多数香蕉都是黄色的时候,模型不需要学习正确的方法来回答香蕉颜色的问题,只要将单词”什么”、”颜色”和”香蕉”与最常见的答案”黄色”联系起来即可,这比通过看图像来判断香蕉的颜色要容易得多
量化每种模态统计捷径数量的一种方法是训练单模态模型,比如在VQAv2中训练的纯语言模型可以在测试集上达到44%的准确率,VQA模型没有放弃这种偏差,因为他们的训练数据集和测试数据集是有着同样的分布,然而在不同分布规律的测试集上评估时,其准确率会显著下降,然而在收集真实数据集时,很难避免这些统计规律,需要采取新的策略来减少来自问题的bias
作者提出了一种训练策略RUBi,用以减少VQA模型的bias,这种策略降低了最biased的样本的重要性,也就是那些不需要看图像模态就能正确分类的样本,它隐式地迫使VQA模型使用两种输入模式,而不是依赖于问题和答案之间 ...
![seada-VQA [对抗数据扩充样本]](https://forever97-picture-bed.oss-cn-hangzhou.aliyuncs.com/img/seadaVQA-1.png)
seada-VQA [对抗数据扩充样本]
Paper Download Address
Code Download Address
Introduction最近的研究表明VQA的性能取决于训练数据的数量,已有的算法总是能从更多的训练数据中受益,这意味着不需要手工标注便能进行数据扩充,从而提升VQA的性能
现有的数据增强方法通过数据扭曲(data warping)或过采样(oversampling)来扩大训练数据集的大小,数据扭曲转换数据并保留其标注,方法包括几何和颜色变换、随机擦除、对抗性训练和风格迁移,过采样生成合成实例并将其添加到训练集中,数据增强可以有效地缓解DNN的过拟合问题
然而在VQA问题上少有对数据增强的研究,因为数据增强的同时需要保持[答案|问题|图像]三元组的正确性,几何变换和随机擦除都难以维持答案的正确性,在文本方面,提出语言转换的通用规则也是很有挑战性的
先前的工作都是基于已知的图像和给出的答案来产生合理的问题,即视觉问题生成,但是这种方法会生成一些奇怪的句子或者存在语法错误,而且生成的数据是从相同分布的原始数据中提取的,并不能减轻过拟合
作者将视觉数据和文本数据作为扩充数据生成语义等价的对抗数据,视觉对 ...
![Grid Feats VQA [回归网格特征]](https://forever97-picture-bed.oss-cn-hangzhou.aliyuncs.com/img/Grid-1.png)
Grid Feats VQA [回归网格特征]
Paper Download Address
Code Download Address
Introduction自深度学习和注意力机制之后,对于跨模态视觉和语言研究来说可能最有影响力的就是bottom-up注意力,区别于用top-down文本输入来关注视觉输入的特定部分,bottom-up注意力采用预训练的目标检测器来识别只跟视觉输入本身有关的突出区域,图像被表示为bbox和区域级的特征,bottom-up特征在之后的研究中被广泛采用
然而是什么造就了区域特征的优良表现?人们会自然地认为主要原因是对单个对象更好的定位,另一个可能的原因是采用多个区域可以很容易地同时捕获图像中的粗级信息和细粒度细节,然而这些潜在的优势是否真的证明了区域特征优于网格特征?
作者发现,在VQA中,从预先训练好的检测器的同一层中提取的网格特征可以与基于区域的对应特征相匹敌,此外,通过在训练过程中进行简单的修改,同样的网格特征可以变得更加有效,并且始终能够达到与区域特征相当甚至更好的VQA精度,作者用消融实验证明了,导致bottom-up特征高准确率的原因有(1)在Visual Genome数据集中收集的大规模 ...
![CVLP [预处理]](https://forever97-picture-bed.oss-cn-hangzhou.aliyuncs.com/img/CVLP-1.png)
CVLP [预处理]
Paper Download Address
Code Download Address
Introduction语言预训练彻底改变了自然语言理解(NLU),与此同时,在视觉分支上提出了视觉语言预训练(VLP),VLP所依赖的网络结构与以往的方法相似,但通过大规模的预训练获得语义信息,使模型具有更好的性能和泛化能力
两种著名的VLP方法LXMERT和ViLBERT均是将标记的视觉区域的特征回归或分类作为自监督学习的代理任务(pretext task),作者在其中发现了一些问题:1) 噪声标注: L2特征回归和分类在视觉基因组中受到噪声标注的影响;2)领域偏置: 由于视觉特征是由视觉基因组上预先训练好的物体检测器生成的,特征回归和标记的区域的分类会使预先训练好的视觉语言模型继承来自视觉的偏置基因组,这使得在其它下游任务上取得较差的泛化能力
为了解决噪声标注和领域差距的问题,文中提出了对比视觉语言预训练(CVLP),借鉴了度量学习中流行的对比学习框架来解决领域偏差和有噪声的标签问题,CVLP用对比学习代替了区域回归和分类,对比学习的目的是区分正样本和负样本,不需要任何注释,因此可以解决有噪 ...
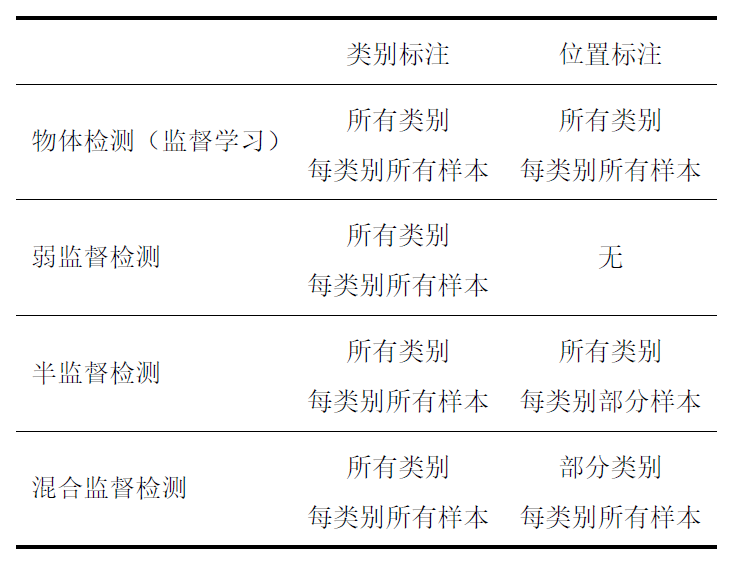
小样本学习
记录一些小样本学习相关知识 (from 物体分类与检测中的小样本学习)
基本概念小样本学习意义
特定任务场景下标注代价高昂,小样本学习旨在探索以低成本的标注形式完成原本高质量大规模标注的数据集才能完成的任务
数据具有长尾分布(long-tail distribution)的特点,数据集中一小部分类别经常出现,大量物体类别对应样本比较稀少,能否利用位于数据分布尾部的先验知识来辅助物体识别算法的训练,而不是简单地依赖这些很难获取到类别的少量样本进行监督学习训练,是很有研究意义和实用价值的
小样本(Small Sample Learning)的定义
测试类别的训练样本完全缺失
部分或者全部测试类别只有少量的训练样本
部分或者全部测试类别训练样本标注信息粗糙,不完整
物体分类中的小样本学习:分为零样本学习,单样本/少样本学习和半监督学习
—— 零样本学习 (Zero-Shot Learning)
指训练集和测试集类别完全不同
零样本学习需要引入额外的辅助信息,辅助信息包含属性特征,物体的文本描述,以及在大型文本语料库上学习到的对应物体类别名称的词嵌入
—— 单样本/少样本学习 (One ...
![VQA as Meta Learning Task [元学习]](https://forever97-picture-bed.oss-cn-hangzhou.aliyuncs.com/img/metaLearningVQA-1.png)
VQA as Meta Learning Task [元学习]
Paper Download Address
IntroductionVQA是一个典型的监督学习任务,一个经过训练的VQA系统只能从一个与训练集非常相似的分布中产生正确的答案,扩展模型知识或扩展它的领域覆盖只能通过重新训练模型来达到,这造成了大量的计算花费,所以这种方法根本无法实现VQA的最终承诺,即回答关于一般图像的一般问题
为了解决这些问题,作者提出了元学习(meta-learning)的方法,使模型学会学习(learn to learn),在测试的时候,模型会从支持集(support set)中学习一些样本以回答给定问题
支持集不是固定的,而且需要注意,支持集可能很大,而且它的大多数元素可能与当前问题无关,它在测试时被提供给模型,并且可以通过附加的示例进行扩展,以扩展模型的能力,所谓的模型”学会学习”就是在测试时动态地识别和利用潜在的大型支持集中的相关示例,因此,向模型提供更多的信息不需要再重新训练,而利用这种支持集的能力极大地提高了系统的实用性和延展性,一个实际的VQA系统最终需要适应新的领域,并随着可用数据的增加而不断改进。这是一个长期的目标,而这项工作只是朝这个方向迈出了 ...
![FPAIT [小样本学习]](https://forever97-picture-bed.oss-cn-hangzhou.aliyuncs.com/img/FPAIT-7.png)
FPAIT [小样本学习]
Paper Download Address
INTRODUCTION构建一个具有人类智慧的AI系统是一个非常大的挑战,这样的AI系统需要具有的其中一个重要的能力是从少量的样本中快速学习到新的内容,特别是多模态场景。最近有很多关于图片或者语言的小样本学习(few-shot)的尝试,但是很少在多模态问题上做小样本学习,这需要同时利用好图片和语义知识。在多模态场景下的小样本学习更具现实意义,比如,亚马逊每周会推出数千件新产品,这些产品在描述和新产品图片中都包含了不常见的词语,共同了解图片/文字及其关系,比只关注图片或文字更能更好地向客户推荐这些新产品
在本文中,作者从小样本图像字幕和VQA两个方面来研究小样本多模态学习,图像字幕和VQA的示例如图所示
对于这两个任务,现有的算法大多集中在监督学习上,因此需要大量的人工标注的图像文本对来进行训练,由于一些单词在少数场景中是不常见的,甚至不曾出现,这些监督算法不能很好地处理这些新单词。现在有一些关于图像字幕和VQA的新出现对象的研究,它们通常利用包含新单词的大型外部文本数据库来学习文本表示。这样,他们的文本模型可以理解新单词,即使这些单词不在 ...
![ReGAT [多类型图结构]](https://forever97-picture-bed.oss-cn-hangzhou.aliyuncs.com/img/ReGAT-1.png)
ReGAT [多类型图结构]
Paper Download Address
Code Download Address
Introduction现有的达到SOTA的VQA系统大部分致力于学习图片和问题的多态联合表示,框架通常为:CNN识别图片区域+RNN编码问题+图片每个区域和问题做联合表示+分类器,这个框架被证明在VQA上是比较有效的
但是图片和自然语言之间仍存在语义鸿沟,比如给定一张斑马的照片,模型可能可以识别黑白像素,但是不知道哪个黑白像素是来自哪只斑马,那么这就使得诸如”最右边的斑马是小斑马吗”以及”所有的斑马都在吃草嘛”这类问题很难被回答,VQA系统不仅需要在图片和语言中识别目标(zebras)和周围的环境(grass),还要理解动作的语义(eating)和位置(at the far right)
这一类的信息需要模型超越单纯的目标检测,学习图像中视觉场景更整体的信息,一个方向是学习目标之间的位置关系(motorcycle-nextto-car),另一个方向是学习目标之间的依赖关系(girl-eating-cake)
基于这个观点,作者提出了Relation-aware Graph Attention ...
![BAN [双线性注意力机制]](https://forever97-picture-bed.oss-cn-hangzhou.aliyuncs.com/img/BAN-1.png)
BAN [双线性注意力机制]
Paper Download Address
VQA任务涉及到许多视觉-语言交叉的问题,因此attention在VQA中能够起到比较好的效果,co-attention可以同时推断视觉注意力和语言注意力,但同时忽略了语言和视觉区域之间的交互作用
作者将co-attention扩展为关注问题和图像的每一对多通道的bilinear attention(双线性注意力),如果给定的问题涉及到由多个单词表示的多个视觉概念,则使用每个单词的视觉注意力分布进行推理比使用单个压缩的注意力分布进行推理更能挖掘出相关信息
作者在低秩双线性池化的基础上提出了双线性注意网络,BAN利用了两组输入通道之间的双线性交互,而低秩双线性池提取了每对通道的联合表示,此外作者还提出了一个多模态残差网络MRN来更有效地利用多重双线性注意图
BAN中用residual summations替代了concatenation,以更高效的参数和性能学习了eight-glimpse BAN,图中展示了一个two-glimpse BAN
文章主要贡献如下:
在低秩双线性池化技术的基础上,提出了学习和利用双线性注意分布的双线性注意网络 ...
![SAAA [层叠注意力机制]](https://forever97-picture-bed.oss-cn-hangzhou.aliyuncs.com/img/SAAA-1.png)
SAAA [层叠注意力机制]
Paper Download Address
文章提出了一个相对简单的结构,经过精心的训练能达到SOTA,整体结构如图:
用LSTM对问题进行编码,用ResNet获取图片的特征,然后用soft attention计算multiple glimpses图像特征,最后进行分类
MethodImage embedding用预训练的CNN来计算图片表示,作者使用的是ResNet,取最后一个池化层,得到的特征大小是14×14×2048维的,然后再对深度维度进行l2范数约束
Question embedding将问题标记并嵌入到长度为p的向量中,然后用LSTM处理
Stacked attention和SAN十分相似,计算图像特征空间维度上的多重注意力分布
每个图像特征的glimpse $x_c$是图像特征在所有空间位置的加权平均,注意力权值$a_{c,l}$对每个glimpse分别归一化,F是一个两层的卷积,共享第一层参数,仅依靠不同的初始化来产生不同的注意力分布
Classifier最后将图像注意力和LSTM结果连接,输入到分类器(两层全连接层),损失函数为
Experiments消融实验 ...
![Conditioned Graph Structures [图结构]](https://forever97-picture-bed.oss-cn-hangzhou.aliyuncs.com/img/graphStructure-1.png)
Conditioned Graph Structures [图结构]
Paper Download Address
文章中主要提出了一个新的,可解释的,基于图形的VQA模型,最近的VQA方法关注于创建新的注意力结构,复杂性不断增加,但未能对场景中物体之间的语义连接建模
作者将scene structure作为先验知识引入,将bbox对象设为图中的节点,基于问题的图边则通过注意力模块来学习,这不仅确定了图像中与问题相关的最相关的物体,而且还确定了最重要的交互作用(例如相对位置、相似性),而无需对图形的结构进行任何手工描述
作者认为,学习一个图结构不仅为VQA任务提供了强大的预测能力,而且通过检查最重要的图节点和边,还可以对模型的行为进行解释
Related workGraph Convolutional Neural NetworksGraph CNNs(GCNs)是一个相对较新的概念,用CNN来图结构化数据,GCN分为两类:频率GCN利用图形信号处理的概念,在欧几里得域上定义图形傅里叶变换,允许在频谱域内以乘法的形式进行卷积,频率GCN有所有训练样本的图结构相同的要求;空间GCN更为工程化,需要定义节点排序和patch操作符,文章的目标是学习基于查询上下 ...
![SAN [层叠注意力机制]](https://forever97-picture-bed.oss-cn-hangzhou.aliyuncs.com/img/SAN-2.png)
SAN [层叠注意力机制]
Paper Download Address
从VQA的数据集中可以看出,VQA回答一个问题通常需要多步推理,比如想要根据下图问答问题”what are sitting inthe basket on a bicycle”,那么首先的找到目标basket和bicycle以及问题中的概念sitting in,然后逐渐排除不相关的对象,最后找出最具有代表性的区域来回答问题(dog)
这篇文章提出了允许VQA进行多步推理的层叠注意力网络(SAN),SAN的整体架构如图所示
系统主要包含三个组件,图片特征提取,问题特征提取以及层叠注意力模型,SAN首先利用问题向量对第一层视觉注意层的图像向量进行查询,然后将问题向量与检索到的图像向量组合成一个精细化的查询向量,再对第二层视觉注意层的图像向量进行查询,随着注意力层次的提高,注意力更清晰地集中在跟答案更相关的区域,最后用问题特征和最高层的图像特征来预测答案
文章的主要贡献有:
提出了层叠注意力机制(SAN)
证明了多层SAN在性能上显著优于之前的SOTA方法
可视化了SAN每一个注意层的输出
SANImage Model图片模块用CNN来获 ...


