React学习记录:实现一个简单的评论系统
项目总览跟着教程开始做第一个React项目,教程见[react小书]
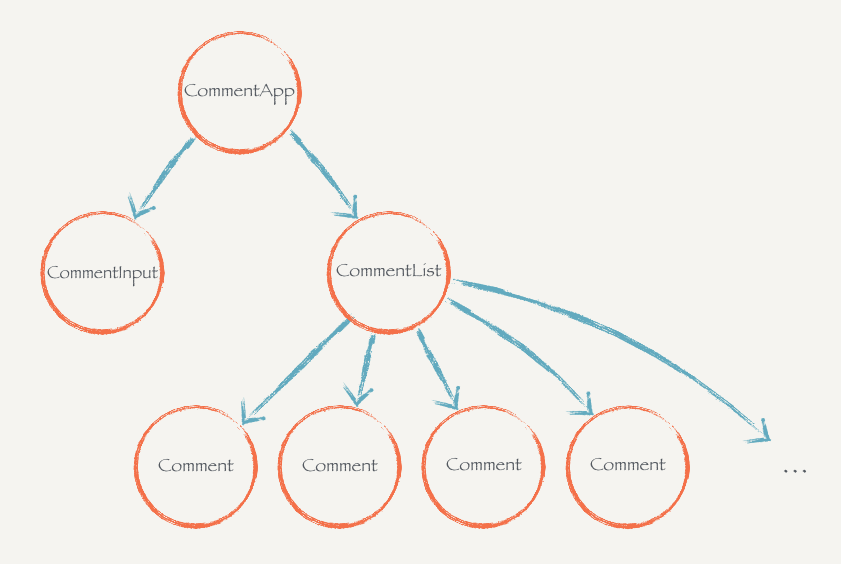
目标是实现如下图所示的一个评论系统
组件划分在React.js中所有的功能都是组件,因此我们要实现一个项目,首先要对项目进行组件的划分,任何可能复用到其它地方的部分,都可以抽离出来作为一个组件,我们对项目进行如下的组件划分
CommentApp组件表示整个评论的应用
CommentInput负责处理用户输入的区域
而Comment则负责每一条评论,通过CommetList组织
项目的组件树如图所示,我们按照组件树自上而下的原则来依次实现组件
组件框架首先我们用creat-react-app来创建一个项目
1creat-react-app comment-app
在src的文件夹下创建四个组件的类文件
12345src/ CommentApp.js CommentInput.js CommentList.js Comment.js
然后我们先自上而下地来实现前三个组件
CommentApp.jsCommentInput.jsCommentList.js123456789101 ...

React学习记录:基本环境安装 (填坑记录)
React.js并不能像D3.js一样直接在js里面包含一个文件即可,而是需要一堆工具和库来辅助,这里呢,有一个非常方便的工具create-react-app,可以直接一键生成需要的工具目录,免去全家桶的安装和配置
根据官方文档先安装了creat-react-app
1npm install -g create-react-app
接着就可以按照文档说明创建一个react工程
123npx create-react-app my-appcd my-appnpm start
npm start失败然后,执行到这一步的时候就挂了,npm start失败了,报错信息是
1npm ERR! code ELIFECYCLE
在项目的Issues里面找到了这个问题的解决方案
Following the stepsIf this has not helpedIf nothing else helps
Delete package-lock.json (not package.json!) and/or yarn.lock in your project folder.
Delete node_ ...
![ICPC2016网络赛 青岛站 H XM Reserves [FFT建模]](https://forever97-picture-bed.oss-cn-hangzhou.aliyuncs.com/img/solution.png)
ICPC2016网络赛 青岛站 H XM Reserves [FFT建模]
题意给定一个方格图,每个点上都有一个值$p_{i,j}$,两个格子之间的距离d被定义为格点中心的欧氏距离,现在给出一个分数的定义,每个格点的分数被定义为所有距离在r以内的格点的p/(d+1)的值,求得分最大的格点的分数
解题思路基本做法是求解每个格点的分数,然后得到其中的最大值
所以对于每个$i$,需要求出$\sum_{d<r}(\frac{p_{x_i-d_x,y_i-d_y}}{\sqrt{d_x^2+d_y^2}+1})$
所有需要对点$i$产生贡献的点$j$的坐标和偏移量$d$满足$x_j+d_x=x_i$,$y_j+d_y=y_i$
构造$A_{i∗M+j}=p_{i,j}$,$B_{d_x * M + d_y} = \frac{1}{\sqrt{d_x^2+d_y^2} +1}$
对于条件距离$r$可以在$B$的赋值时做判断处理
考虑到$d_x$和$d_y$的取值范围为$[R,-R]$,我们对偏移量做偏移处理
即$B_{(i + R) * M + j + R} = \frac{1}{\sqrt{i ^ 2 + j ^ 2} +1}$
则$A$和$B$的卷积$C_{(i ...

VIS2019论文整理(3)
[V] VAST,[I] InfoVis,[S] SciVis
VIS2019论文整理系列的最后一篇
之前的内容见:
[VIS2019论文整理(1)]
[VIS2019论文整理(2)]
Volume Visualization[S] Void-and-Cluster Sampling of Large Scattered Data and Trajectories [PDF]
本文提出了一种基于统计抽样的分散数据的数据约简技术。该空隙和聚类采样技术找到一个代表子集,最优分布在空间领域的蓝色噪声。此外,它可以适应给定的密度函数,作者使用它来采样多变量值域中的高复杂度区域更多的人口。此外,该采样技术隐式地定义了样本的顺序,从而支持渐进式数据加载和连续的详细级别表示。并将技术扩展到采样时间依赖的轨迹,例如在一个时间间隔内的路径线,使用一种有效的迭代方法。此外,团队引入了一个局部和连续的误差度量来量化一组样本代表原始数据集的程度,在抽样时应用这个误差测量来指导抽样的数量。最后,作者团队使用这个误差度量和其他量来评估算法的质量、性能和可扩展性。
[S] FeatureLego: Vo ...

从零开始的算法竞赛入门教程:IMOS
前言差分是竞赛中非常常用的技巧,正巧这次的USACO题目中可以用上差分,顺便做一个普及
这一个小节大概就只准备讲这一题,因为剩下的题目只涉及到进制转换和回文判断,属于对语法的巩固,没有太多想讲的知识点
题意[Milking Cows]
给定若干条线段(数量不大于5000),左右端点范围[0,1000000],求没有被线段覆盖的最长区间和被至少一条线段覆盖的最长区间
题目分析首先可以得到这个题的一个非常朴素的做法,将每个线段在数组中对覆盖到的位置+1,然后扫描整个区间得到答案,USACO的原数据较弱,所以我看到有些同学是这么过的,但是这么做的复杂度是O(nL)的,并不是一个合理的复杂度
IMOSIMOS又被称为累积和法,其实就是通过前缀和以及差分思想来维护数据,在数据结构题中这个技巧非常实用
举一个简单的例子:
有一辆公交车,现在告诉你每个人上车和离开的时间点,要求查询任意时刻车上的人数
IMOS的做法就是,对于每个人,我们只需要在其上车的时间点+1,下车的时间点-1,计算这个时间表的前缀和,就可以得到关于时间点的答案数组
计算前缀和
二维的处理方法看下图应该就能看懂
图是从我自己 ...
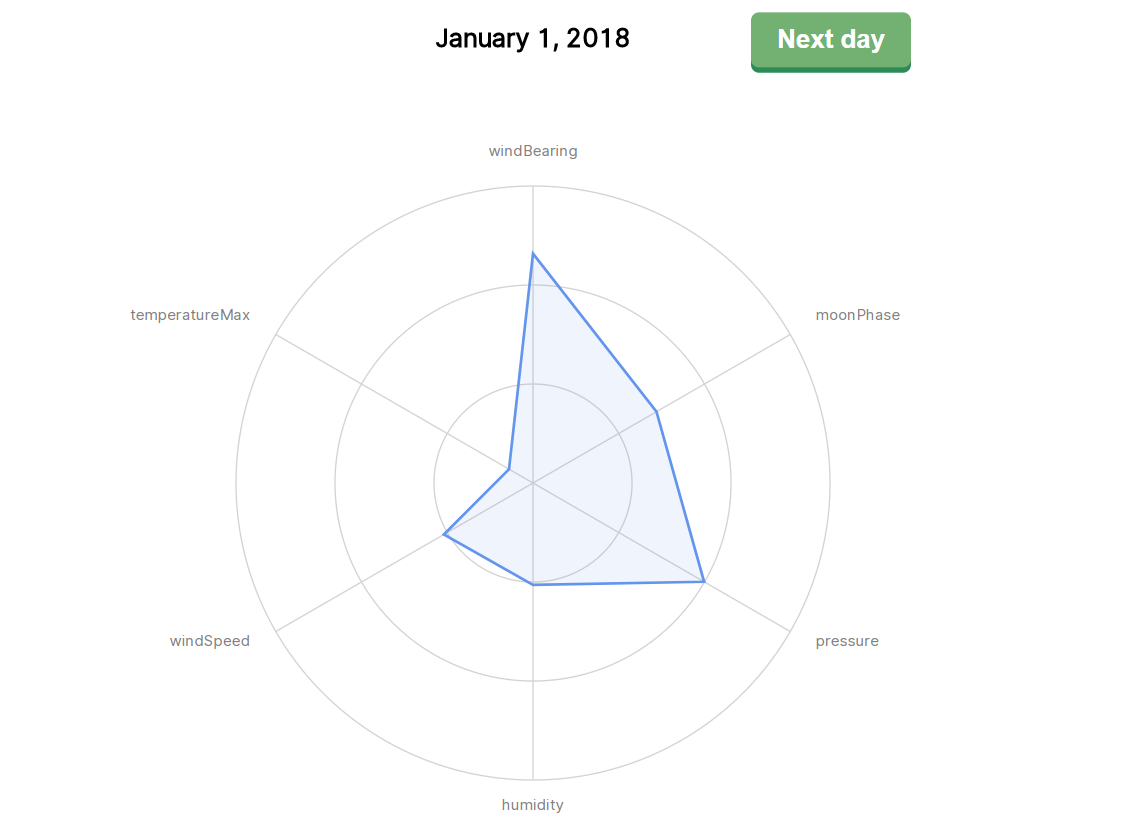
D3学习记录:雷达图
这回我们用祖传的数据来画一个雷达图
绘制边框参数和数据载入的过程和之前别无二致,准备工作完成之后,我们先来绘制几个同心圆,来作为雷达图的基础边框
123456789const axis = bounds.append("g")const gridCircles = d3.range(4).map((d, i) => ( axis.append("circle") .attr("cx", dimensions.boundedRadius) .attr("cy", dimensions.boundedRadius) .attr("r", dimensions.boundedRadius * (i / 3)) .attr("class", "grid-line")))
我们准备在雷达图上显示六种属性,因此接下来我们要画对应的六个坐标轴,和同心圆一样,我们也可以用map来实现
1234 ...
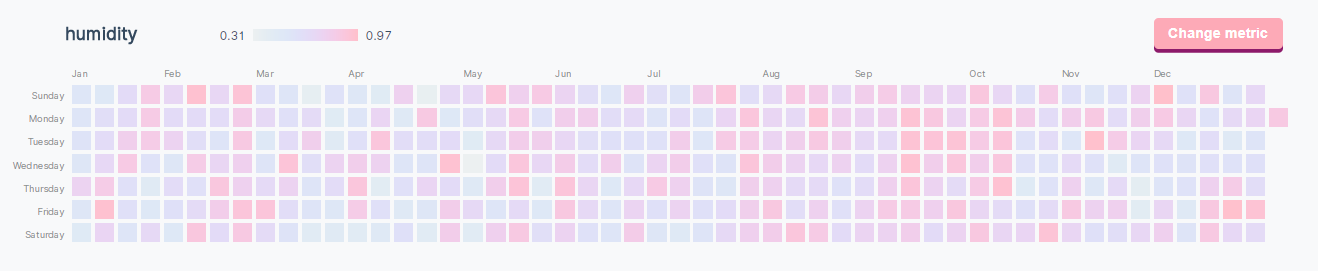
D3学习记录:热图
常用git的同学可能对热图(heatmap)已经很熟悉了,就是这个东西
我的contribution真是丢人,希望之后可以填的更满一点
现在我们来做一个自己的heatmap,当然还是熟悉的那个数据
预处理先把数据读入,然后做一些预处理
12345678910111213const pathToJSON = "./data/nyc_weather_data.json"let dataset = await d3.json(pathToJSON)const parseDate = d3.timeParse("%Y-%m-%d")const dateAccessor = d => parseDate(d.date)dataset = dataset.sort((a, b) => dateAccessor(a) - dateAccessor(b))const firstDate = dateAccessor(dataset[0])const weekFormat = d3.timeFormat("%-e")const x ...

从零开始的算法竞赛入门教程:环的处理
前言环是竞赛题当中一个比较常见的条件,在不同情况下需要不同的处理方法,最常见的是下标取余和破环成链,别的技巧因为涉及更多算法暂且不提,大家之后遇到可以自行整理归纳
第一节结束,大家应该基本掌握了语法,从本篇开始,基本不再放出具体的题目代码,只讨论思路和算法,或者给出部分核心代码,有些单纯练习,并没有新鲜技巧或者新内容引入的题也会跳过
题意[Broken Necklace]
有一条由N个红色的,白色的,或蓝色的珠子组成的项链,要求在某点打破项链,展开成一条直线,从两端往里收集珠子,收集珠子的时候,一个被遇到的白色珠子可以被当做红色也可以被当做蓝色,每端收集珠子时当遇到不同颜色的珠子就停止收集,问能够收集到的最多的珠子数量
题目分析首先有一个非常简单的思路,枚举每一个断点,然后往两边获取珠子直到不能获取为止,但是本题给出的是一个环,如果获取珠子的过程中跨越了n-1分界线,就要用取余来计算下一个位置,并且比较容易写错
这里有个比较好的方法就是,破环成链,这是一个非常常用的技巧,具体做法就是,将表示环的数组复制一遍,接在原来的数组后面,那么不需要跨越分界线,原来所有环的遍历情况在链上就能处理
...
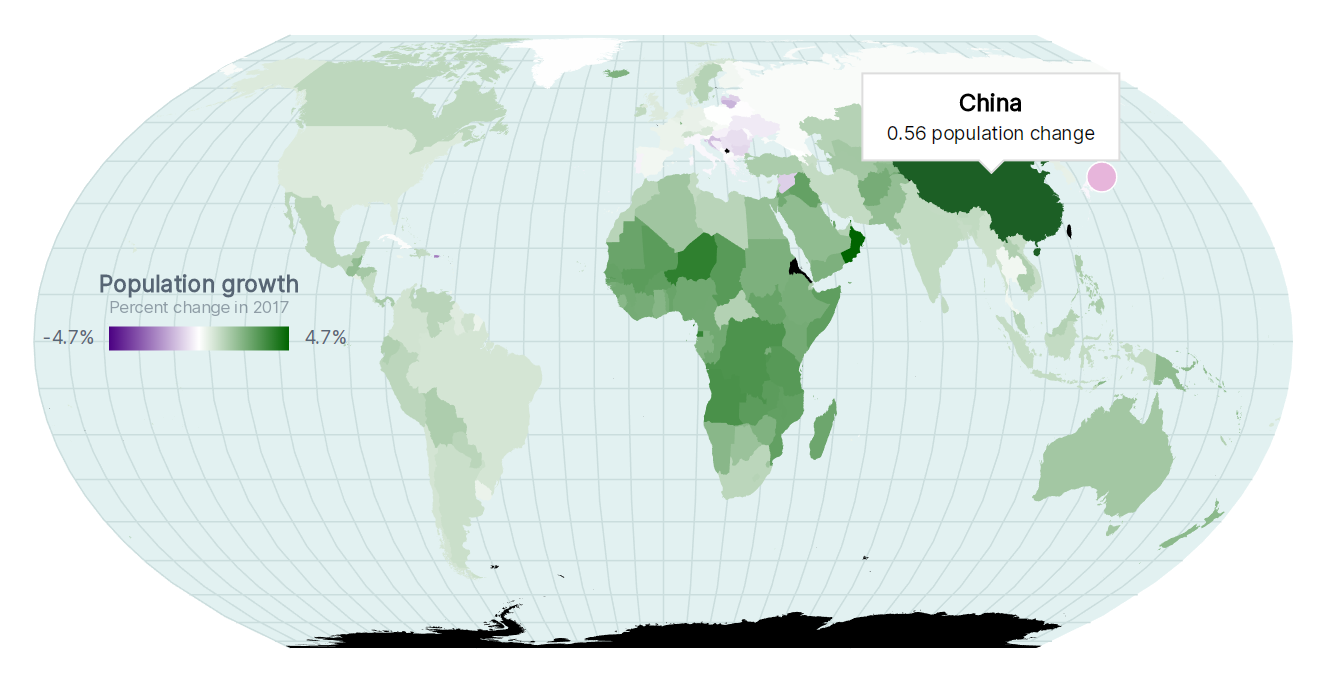
D3学习记录:地图
在d3中地图的创建通常用d3-geo来实现的,GeoJSON是一种用于表示地理结构(几何图形、特性或特性集合)的格式,我们选择Natural Earth来作为练手数据
数据读入与参数设置首先读入数据
12const countryShapes = await d3.json('./data/world-geojson.json')const dataset = await d3.csv('./data/world_bank_data.csv')
console.log一下我们可以看到json数据的内容,其中包含了四个关键字:crs, features, name, type
我们在feature里面挑选关键词并创建访问器函数,通过访问国家ID来找到人口增长数据集中的度量值
12const countryNameAccessor = d => d.properties["NAME"]const countryIdAccessor = d => d.properties["ADM0_A3_IS"] ...
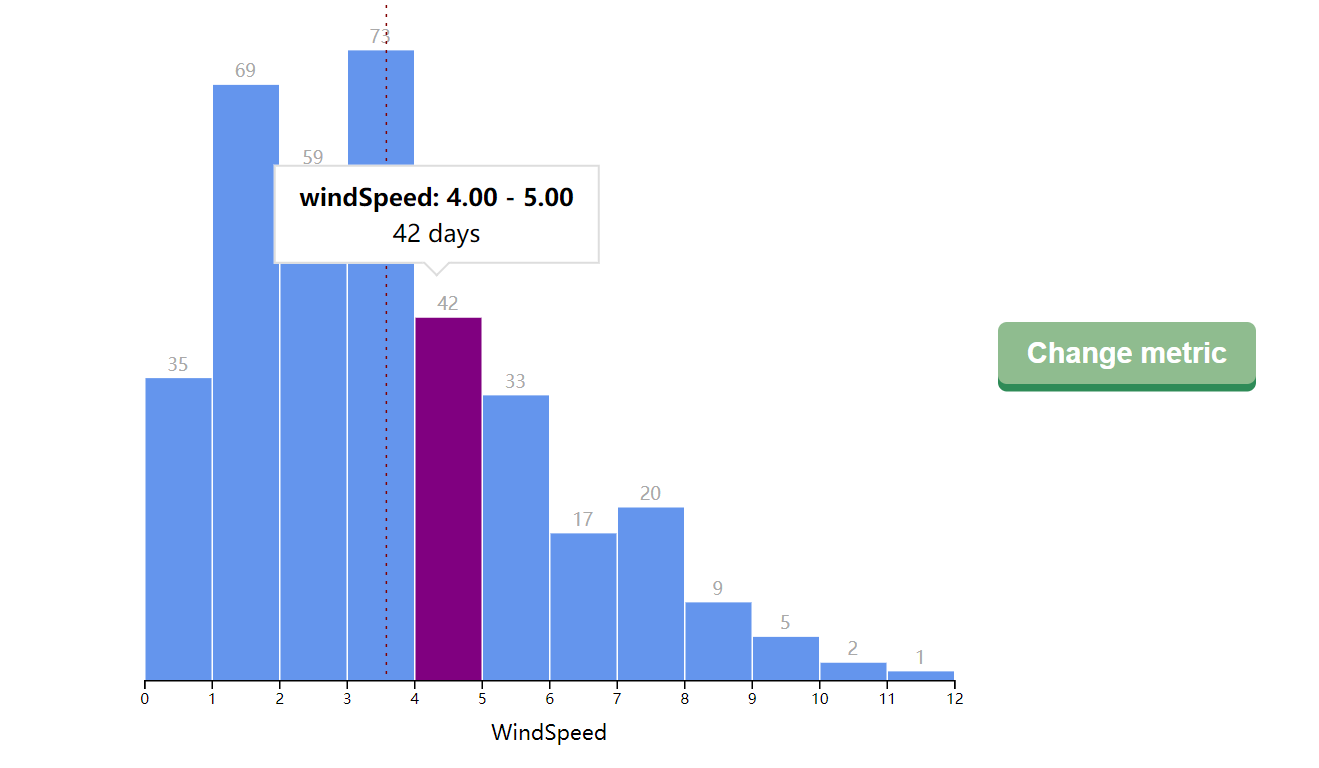
D3学习记录:交互
交互即对于键盘和鼠标对元素的操作做出反应
我们先对柱状图加入一些交互操作
交互的实现非常简单,.on(事件,操作函数),比如我们想在矩形上做出一个鼠标移入的操作,只要实现如下代码即可,这样就可以使得矩阵在鼠标移入的时候变成紫色
1234binGroups.select('rect') .on('mouseenter', function (d) { d3.select(this).style("fill", "purple") })
然后就发现当鼠标移开之后还是紫色的,这说明我们还需要加入一个鼠标移开的事件,这样就可以保证只有鼠标覆盖到的矩阵是变了颜色的
123.on('mouseout', function(d) { d3.select(this).style("fill", "cornflowerblue")})
然后我们就可以在function里面加入更多的操作,比 ...
VIS2019论文整理(2)
[V] VAST,[I] InfoVis,[S] SciVis
继续整理VIS2019的论文内容,之前的内容见[VIS2019论文整理(1)]
Evaluation & Reproducibility[I] Toward Objective Evaluation of Working Memory in Visualizations: A Case Study Using Pupillometry and a Dual-Task Paradigm [PDF]
认知科学已经在许多应用领域建立了广泛使用和验证的评估工作记忆的方法,但很少有研究使用这些方法来评估可视化对工作记忆的影响。使用经过验证的方法来测量工作记忆的信息可视化研究之所以缺乏,部分原因可能是由于缺乏为可视化研究的独特需求量身定制的跨领域方法论指导。本文提出了一套清晰、实用、有经验验证的视觉任务工作记忆评估方法,并为读者选择合适的工作记忆评估范式提供了指导。以地理空间数据为例,阐述了在视觉-空间聚合任务中评估工作记忆的多种方法。结果表明,使用双任务实验设计(同时完成多个任务而不是单任务)和瞳孔扩张可以揭示与 ...
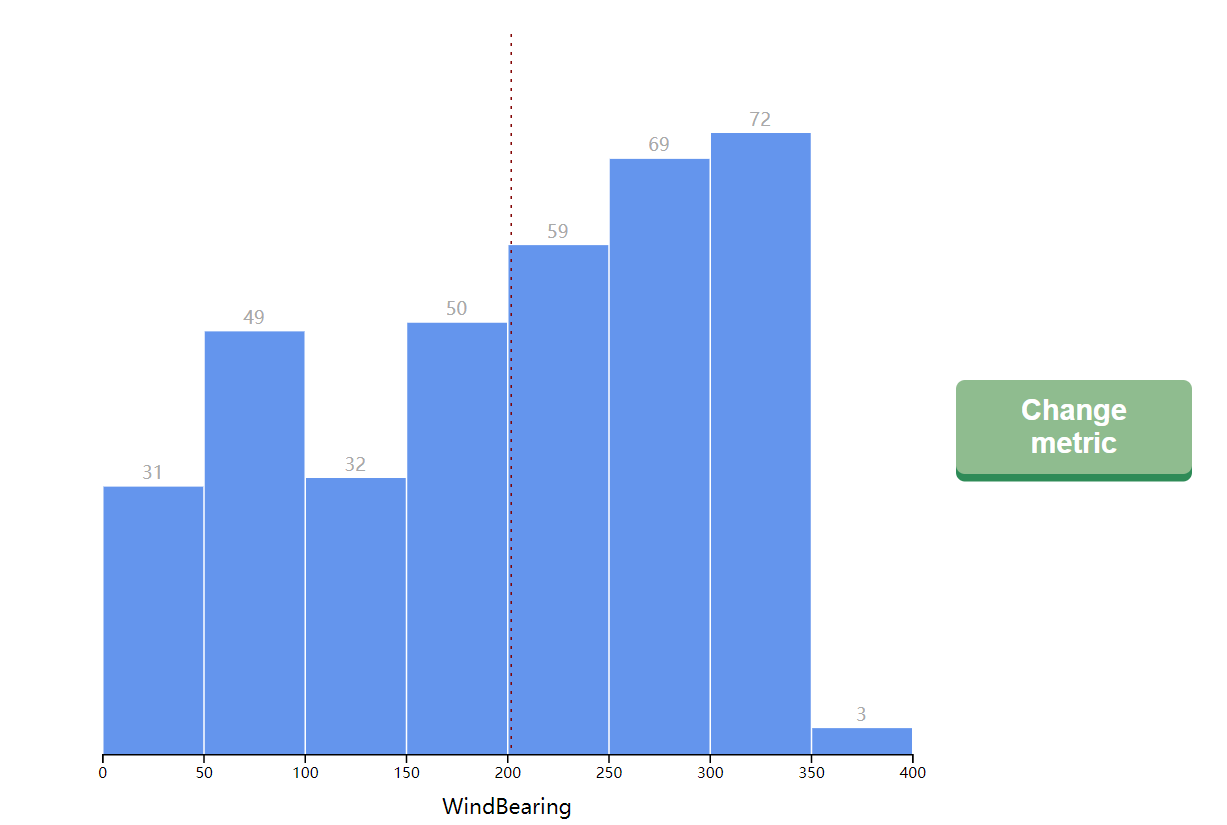
D3学习记录:动画与过渡
动画和过渡是D3中非常重要的一块内容
为柱状图添加动画首先我们学习一下如何对之前的柱状图增添动画
之前我们完成柱状图之后,可以通过调用函数生成多个不同的柱状图,现在我们希望用一个按钮来完成柱状图之间的切换,因为每个柱状图中柱子的数量是不同的,因此这就涉及到了d3中各种状态的处理,当exit态中一个柱子退出图像或者enter态中一个柱子加入图像的过程,我们肯定不希望是直接消失或者直接出现的,这样会非常丑,于是,就需要过渡和动画
首先设置动画过渡的时长
12const exitTransition = d3.transition().duration(500)const updateTransition = d3.transition().duration(1000)
插入动画呢,只要在希望过渡的属性之前加入.transition(updateTransition)即可
我们得设置进入状态,更新状态,以及退出状态的不同属性值,然后在remove之前和append之后插入过渡动画,使得图表转化平滑
先来设置进入状态的属性
123456789101112const newBinGroups ...

D3学习记录:柱状图
还是熟悉的数据,这回来做一个柱状图
[数据下载地址]
准备工作还是熟悉的数据载入
12const pathToJSON = "./data/nyc_weather_data.json"const dataset = await d3.json(pathToJSON)
接着设置参数
1234567891011121314151617const width = 600let dimensions = { width: width, height: width * 0.9, margin: { top: 30, right: 10, bottom: 50, left: 50, },}dimensions.boundedWidth = dimensions.width - dimensions.margin.left - dimensions.margin.rightdimensions.boundedHeight = dimension ...

D3学习记录:散点图
这次来画一个散点图,用的还是上次画折线图的数据
[数据下载地址]
准备工作读入数据的方式和之前是一样的
1const dataset = await d3.json("./data/nyc_weather_data.json")
这次采用湿度和露点作为两个属性
12const xAccessor = d => d.dewPointconst yAccessor = d => d.humidity
我们准备画一个正方形的散点图,所以我们现在计算它的边长
1234const width = d3.min([ window.innerWidth * 0.9, window.innerHeight * 0.9,])
同样的,设置一个参数表,并计算bound的高和宽
12345678910111213141516let dimensions = { width: width, height: width, margin: { top: 10, right: 10, b ...

从零开始的算法竞赛入门教程:年月日与星期的计算
前言这次要讲解的题从本质上说就是一个简单的模拟题,模拟题在竞赛中是一类简单而复杂的问题,简单是因为不需要太过高深的算法就能够解决,而复杂指的是,你需要准确地掌握题目中的每一个条件,用最简单明快的方式去实现
题意[Friday the Thirteenth]
已知1900年1月1日是星期一,4,6,11和9月有30天,其他月份除了2月都有31天。年份可以被400整除的世纪年或者被4整除的非世纪年是闰年,世纪年指的是年份为100整数的年
写一个程序来计算从1900年起,在n年里13日落在星期六,星期日,星期一,……星期五的次数
分析与代码首先用一个常量来记录1900这个年份数字
1const int base = 1900;
每年各个月份的天数其实也是一个常量,我们用一个数组来将其记录下来,方便查询
1int months[12] = {31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31};
这里我只记录了非闰年的情况,为了清晰起见,闰年也可以通过这种方式记录
之后的基本思路就是每个月的天数不断累加,判断那个月的13号是星期 ...

D3学习记录:折线图
最近准备刷一遍 Fullstack D3 and Data Visualization,系统地学一下d3,顺便记录一下学习过程
首先是实现一个小目标:画一个纽约天气折线图
数据载入与查看第一步,载入数据
1234async function drawLineChart() { const dataset = await d3.json("./data/nyc_weather_data.json"); console.log(dataset);}
以下所有的代码都是默认在drawLineChart异步函数中书写
然后可以控制台输出来看看
365天的天气,每天还有一堆属性,这种情况下有个更方便的查看数据的方式,console.table,我们来查看第一天的数据
1console.table(dataset[0])
nice
初始参数设置用xAccessor和yAccessor来绘制x轴和y轴上的点
y轴用每天的最高气温作为标度,而x轴则采用时间
1const yAccessor = d => d.temperatureMax ...

从零开始的算法竞赛入门教程:标准模板库
前言标准模板库,简称STL,包含有大量的模板类和模板函数,是C升级到C++的++里面包括的部分,非常方便实用,是竞赛中的必备技能之一,当然STL和C++语法一样,想介绍详细,也会变成厚厚的一本书(《 STL源码剖析 》),所以这和语法的学习方法是一样的,不断学习需要用到的即可,从doc中学习最标准的书写方式,从别人的代码中学习一些奇技淫巧高效的使用方法
C++ Reference
题意[Greedy Gift Givers]
给定互送礼物的列表,确定每个人收到的礼物价值比送出的多多少
每个人都准备了一些钱来送礼物,而这些钱将会被平均分给那些将收到他的礼物的人
INPUT1234567891011121314151617181920212223245davelauraowenvickamrdave200 3lauraowenvickowen500 1daveamr150 2vickowenlaura0 2amrvickvick0 0
OUTPUT12345dave 302laura 66owen -359vick 141amr -150
题目分析当你第一次拿到这种题的时候,可能会觉得 ...
VIS2019论文整理(1)
[V] VAST,[I] InfoVis,[S] SciVis
整理一下VIS2019的论文内容(Abstract为主)
本来打算全部整理在一篇文章里的,发现太乱了,所以一篇就放十个专题左右吧
[VIS2019论文整理(2)]
VIS Best Paper[V] FlowSense: A Natural Language Interface for Visual Data Exploration within a Dataflow System [PDF]
数据流可视化系统允许用户构建数据流图,数据流图由查询和可视化模块组成,以指定系统功能,从而实现灵活的可视化数据探索。然而,学习数据流图的使用带来的开销往往会阻碍用户。
基于此,文章设计了一个用于数据流可视化系统的自然语言界面——FlowSense,利用自然语言处理技术来协助数据流图的构造。FlowSense使用带有特殊话语标记和特殊话语占位符的语义分析器来推广到不同的数据集和数据流图。它明确地将已识别的数据集和图表特殊话语呈现给用户,用于数据流上下文感知。使用FlowSense,用户可以通过简单的英语,更方便地扩展和调整 ...

SMAP:安全多方联合降维可视化方案
IEEE引用格式:J. Xia et al., “SMAP: A Joint Dimensionality Reduction Scheme for Secure Multi-Party Visualization,” 2020, [Online]. Available: http://arxiv.org/abs/2007.15591.
文章简介在多方数据被融合到一个站点来建立点集关系时,传统的可视分析方法(如降维)可能会暴露数据隐私,可视分析中的数据隐私是一个重要的需求,比如几个医院想要执行其病人数据的联合分析,同时保持他们的数据隐私
应用可视化技术帮助人们理解多方高维数据的时候,通常会采用降维技术,比如主成分分析(PCA),多维尺度(MDS),t-SNE,将所有的数据点投影到一个公共空间,然而降维技术首先就会破坏数据的隐私性,比如传统的降维方法是为单站点计算设计的,需要从所有站点收集原始数据来创建联合嵌入,如果在多方数据之前简单地匿名化数据又会减少数据的效用,导致不准确的布局,而且匿名的数据也有被保护的必要。其次当其他人采用可视化设计来检查隐私敏感数据时,数据隐私也会受到威胁
...

从零开始的算法竞赛入门教程:基础语法与函数思想
前言针对没有任何编程经验的同学写一份C++的教程是十分困难的,因为C++光是语法部分就能填充一本如同字典一般厚的书,而在算法竞赛中,我们仅仅是选择学习一些需要用到的,足以完成问题求解即可
学习程序语言和学习语言的过程是类似的,可以通过反复地模仿来熟悉,不断地尝试来积累,然后慢慢地能够做到自我创造,所以呢,不要踌躇不前,不要觉得难以下手,去模仿,去写去尝试
本教程基于USACO Training,结合题目内容讲解,随缘更新,如果对零基础的同学能够起到一些帮助,那就再好不过了
由于知识的诅咒,我可能已经很难明白初学者可能会遇到什么问题了,如果感觉写的某些东西晦涩难懂,欢迎与我交流,但是最好,你可以善用搜索引擎和手头的工具书来自行找到解决问题的方法
题意[Your Ride Is Here]
将两个字符串按照规则转化成数字,判断是否相等
规则:A-Z对应1-26,将串中每个字母转化成数字,相乘后对47取模
INPUT12COMETQHVNGAT
OUTPUT1GO
开始写代码首先写下头文件和命名空间
12#include <bits/stdc++.h>using namesp ...


