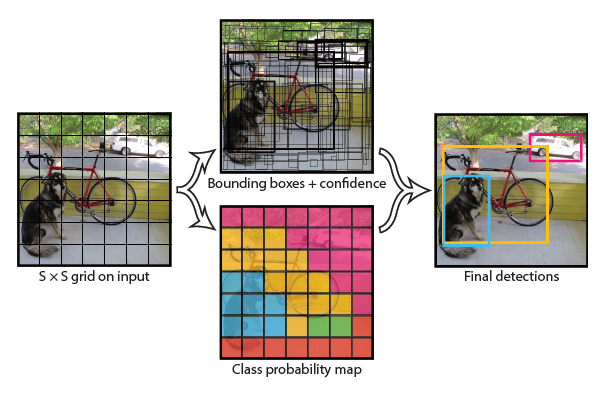
YOLO:实时目标检测
基本YOLO模型能够以每秒45帧实时处理图像,较小版本fastyolo每秒处理155帧,同时仍能达到其它实时探测器2倍的mAP
YOLO的意思就是You only look at once,从名字上听起来就非常快,在RCNN系列的网络中采用的是two-stage方法,即先生成候选框,然后对候选框进行分类,而以YOLO为代表的one-stage方法则是直接回归到类别概率和物体坐标
Yolo核心思想Yolo的思想非常简单,就是将输入的图像划分成$S\times S$的格子,如果检测物体的中心在某个格子内,那个这个格子就负责检测这个物体
每个格子会预测B个bbox以及其对应的置信度(confidence scores),置信度表示bbox包含一个物体的确定程度和bbox的准确度,所以其计算公式为
$Pr(Obj) \cdot IoU(pred,GT)$
公式的含义是,若格子中有物体,则置信度为$IoU(pred,GT)$,否则为0
每个bbox由5个预测组成:x、y、w、h和置信度。(x,y) 坐标表示长方体相对于网格单元边界的中心。w和h对图像的宽度和高度进行了预测。置信度预测表示 ...

Cascade R-CNN:级联RCNN以提升检测质量
Cascade RCNN 采用级联的方式,几乎对任意的RCNN都起到提升2到4点AP的作用
Faster R-CNN系列改进回顾
R-CNN回顾
Fast R-CNN回顾
Faster R-CNN回顾
RCNN系列存在的问题在RCNN系列中IoU的阈值决定了一个RoI属于正样本或是负样本,如果我们抬高阈值,则得到的RoI肯定是更接近真实物体,那么训练得到的检测器肯定会更为准确 (更好的proposal得到更好的bbox)
但同时会导致两个问题:
过拟合,更高的IoU阈值会导致选出更少的正样本 (如下图所示),正负样本的严重不均衡导致训练过拟合
严重的mismatch问题
Mismatch问题
训练阶段bbox回归学习的正样本是和GT的IoU大于阈值的Proposals,而测试阶段由于没有GT,用于bbox回归坐标的正样本是所有的Proposals,可能存在IoU小于阈值的,会导致性能下降,随着IoU阈值的提高,问题会变得更加严重
实验与发现
作者对不同的IoU阈值设置做了三组实验,c图展示了proposals的分布,横纵轴为经过bbox回归前后的候选框IoU分布, ...
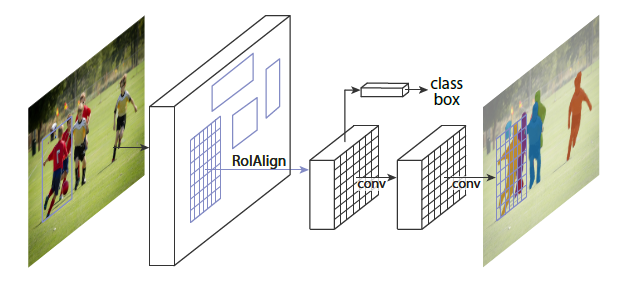
Mask R-CNN:引入Mask分支以实现实例分割
Mask RCNN 是基于Faster RCNN提出的,在高效完成目标检测的同时实现了高质量的实例分割
Faster R-CNN系列改进回顾
R-CNN回顾
Fast R-CNN回顾
Faster R-CNN回顾
Mask R-CNN相对于Faster R-CNN的改进主要有三点
引入FPN结构进行特征提取
采用RoI Align代替RoI pooling
在分类和回归的分支基础上,加入Mask分支
特征金字塔FPN使用单一尺寸的特征(Faster R-CNN)的做法,在经过CNN逐层的下采样,到达最后特征层的时候图片中小物体的有效信息较少,检测性能急剧下降 (图b)
而图像金字塔 (图a) 将输入图片做成多个尺寸,来生成不同尺度的特征来解决多尺度的问题,这种做法计算量大,非常耗时
特征层分层预测 (图c) 语义信息差距太大,高分辨率的低层特征不具备足够的检测能力
基于以上几种做法,提出了特征金字塔FPN (图d),从高层携带信息传给低层,再分层预测
首先自底向上提取语义信息,然后依次进行上采样,各层进行$1\times 1$卷积降低通道数 (使通道数变为256) ...

Faster R-CNN:通过RPN实现实时目标检测
Faster RCNN 用 RPN 优化了候选框初选的过程,提高了RCNN系列网络的综合性能
首先回顾一下R-CNN和Fast R-CNN
R-CNN回顾
Fast R-CNN回顾
可以看到所谓R-CNN的缺陷,主要体现在RoI上
RoI特征提取造成较大时间消耗 (每个RoI用CNN提取特征)和内存消耗 (RoI提取需要先存取)
RoI获取过程时间消耗太大 (罪魁祸首Selective Search)
Fast R-CNN解决了RoI的第一个问题 (同时也搞定了多阶段训练的问题),而Faster R-CNN主要是解决RoI的第二个问题,用RPN来替代耗时巨大的Selective Search
Faster R-CNN分为两个模块,第一个模块是用于产生区域框的深度全卷积网络,第二个模块就是Fast R-CNN目标检测器
RPN网络如图所示,RPN(Region Proposal Network)的作用就是以feature map作为输入,得到Region Proposal (候选区域)
特征图中的点与原图中的位置的对应关系只与CNN中经过的池化层数量有关,因为在Fas ...

Fast R-CNN:引入RoI池化以共享卷积计算
Fast RCNN 在训练速度上达到 RCNN 的9倍,测试速度达到其213倍,同时在PASCAL VOC 2012测试集上mAP达到66%
RCNN和SPPnet首先回顾一下RCNN中存在的一些问题
训练是多阶段的 (CNN + SVM + bbox regressor)
训练耗时占空间 (每个候选框的特征需提取并保存)
测试速度慢 (47s/img)
R-CNN回顾
SPPnet是RCNN的改良版本,在RCNN中,需要先提取候选框中的特征,然后将每个候选框的特征单独输入CNN中做卷积操作,而SPPnet的核心思想就是从feature map中提取ROI(候选框)特征
这将面临两个问题:
原始图像的候选框如何映射到特征图 (卷积层的输出)
候选框对应的特征如何满足全连接层的输入要求 (特征无法像图片一样拉伸或者填充)
为了解决全连接层输入大小固定的问题,SPPnet提出了空间金字塔池化 (SPP,spatial pyramid pooling),不管输入的特征图大小,均用三种不同尺度的滤波器做池化,最终得到$4\times 4$,$2\times 2$,$1\ ...

R-CNN:Region Proposal + CNN特征
RCNN第一次将CNN引入目标检测领域,相比之前(利用SIFT和HOG提取)将mAP提高30%以上,实现了53.3%的mAP
mAP指标补充一下mAP指标的背景知识
mAP(mean Average Precision),字面意思,各类别 AP(检测精度) 的平均值
AP(某类别检测精度) 的计算方式则是P-R曲线下包围的面积(积分计算),P-R曲线的P指的是准确率(Precision),R指的是召回率(Recall),召回率也叫查全率
他们的计算公式分别为
$P=\frac{TP}{TP+FP}$
$R=\frac{TP}{len(GTs)}$
公式中的TP,FP含义如下
TP(True Positive):IoU大于阈值的检测框数量(同一个GT(Ground Truth)的框只算一次)
FP(False Positive):IoU小于等于阈值的检测框数量or同一个GT的多余检测框
IoU(Intersection of Union) 用于衡量预测框和真实框的贴合程度
$IoU_{A,B}=\frac{S_A \ \cap \ S_B}{S_A \ \cup \ S_B}$
...

爬虫学习记录:动漫之家漫画爬取
爬虫时效性低,代码可能随时间失效,但爬虫思路不变
获取漫画章节名首先,随便在排行榜上选了一个比较短的漫画《雪屋》 (没看过,并非推荐)
漫画链接
审查一下元素,发现代表章节的都在class属性为list_con_li的<ul>标签下的<a>标签中,但是是倒序的
所以我们找到包含对应class的<ul>,然后遍历里面的<a>标签,通过往dict前端插入将倒序调整成顺序
123456789101112131415161718import requestsfrom bs4 import BeautifulSoup target_url = "https://www.dmzj.com/info/xuewu.html"r = requests.get(url=target_url)bs = BeautifulSoup(r.text, 'html')list_con_li = bs.find('ul', class_="list_con_li")comic_list ...

爬虫学习记录:用Requests和bs4爬一本小说
爬虫时效性低,代码可能随时间失效,但爬虫思路不变
工具介绍首先介绍一下采用的工具requests和bs4
这里主要用request.get向浏览器发起get请求,利用bs4中的Beautiful Soup对html内容进行解析,提取真正需要的内容,文档如下
RequestsRequests quickstart
Beautiful SoupBeautiful Soup中文文档
页面爬取首先用requests来获取小说页面的html,这里选择笔趣看的《心魔》一书
打开第一节,将网址记录下来
在pycharm中写下如下代码,就可以获取到该页面的html
123456import requestsif __name__ == '__main__': target = 'https://www.bqkan.com/11_11154/4135502.html' req = requests.get(url=target) print(req.text)
结果如图所示
这时候就要用上我们的BeaufifulSoup
我们发现需要的 ...

HTML学习记录:多媒体与超链接
本文所有展示效果都是使用了博客css后的效果,并非单纯html效果
记录一下html媒体嵌入与超链接的方法
超链接先介绍一下最基础的超链接方式
1<a href="/2020/12/14/html2/">HTML学习记录:文字排版</a>
HTML学习记录:文字排版
当然我们还可以为超链接增加图片,这种方式叫块级链接
123<a href="/2020/12/14/html2/"> <img src="https://forever97-picture-bed.oss-cn-hangzhou.aliyuncs.com/img/html2-1.png"></a>
效果如下所示,点击图片即打开链接
文档内链接除了链接到别的网页,还可以在html文档的内部进行链接,不过首先要在链接的元素上加入id,比如我们给上文的图片链接加个id,然后尝试去链接到它
123456<!--加入id--><a href="/2020/12/14 ...

HTML学习记录:文字排版
本文所有展示效果都是使用了博客css后的效果,并非单纯html效果
记录一下html中的排版标签
标题与段落1234567<h1>顶级标题</h1><h2>二级标题</h2><h3>三级标题</h3><h4>四级标题</h4><h5>五级标题</h5><h6>六级标题</h6><p>段落</p>
效果如下
顶级标题
二级标题
三级标题
四级标题
五级标题
六级标题
段落
列表列表分为无序列表(Unordered Lists)和有序列表(Ordered Lists),以及自定义列表
无序列表123456<ul> <li>元素一</li> <li>元素二</li> <li>元素三</li> <li>元素四</li></ul>
效果如下
元素一
元素二
元素三
元素四
...
利用Github Action实现全自动部署
Hexo博客在部署的时候,随着文章越来越多,编译的时间也会越来越长,而通过Github Action,我们可以在完成博客编写和修改之后直接将改动push到远程仓库,让其自动完成编译和部署
创建存放源码的私有仓库首先,需要创建一个用来存放Hexo博客源码的私有仓库
之后我们需要将源码push到这里
采用私有仓库的原因是以下的操作会使用token,如果token被盗用则盗用者可以任意操作你的git仓库
获取TokenGithub Token在github的Settings中选择 Developer Settings -> Personal access tokens -> generate new token,token名字任意,勾选上repo项
快速访问
确定生成后,将token复制下来保存好
官方提示:Make sure to copy your new personal access token now. You won’t be able to see it again!
就是说这个只显示一次,如果你丢失了这个token,那么你得重新再生成一个
Gitee ...

使用Vercel加速博客访问
Vercel可以提供免费的serverless和全局CDN服务,并且可以根据git上hexo博客的master(main)分支是否变动来启动自动部署
在Vercel上部署
首先访问Vercel,在右上角点击注册,新建项目并选择From Git Repository
VercelVercel官网地址
在页面输入git项目地址
然后对项目进行确认,如果不是自己的项目,系统会自动帮你fork到自己的库
选择person account后,需要为自己的Github安装Vercel,All repositories表示为所有的git仓库安装,Only select repositories表示只为当前仓库安装
Vercel会识别出hexo博客的静态页面,点击continue即可
最后import project,Vercel的PROJECT NAME可以自定义,但是之后不支持修改
然后就可以访问Vercel部署的页面了
完成
可以感觉到访问比github快多了
forever97forever97's blog
自定义域名
在Project->Settin ...

HTML学习记录:基础概念
HTML框架在VSC上写下html,就会有一个小窗,选html:5
然后就可以快速得到一个html的框架
1234567891011<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Document</title></head><body> </body></html>
然后我们对这个框架里面的内容稍做解释
<!DOCTYPE html>负责告诉浏览器文档的标准:HTML/XML
lang="en",用于指定页面的语言类型
<head>头标签里面表示页面的配置
<meta&g ...

Space-Reclaiming Icicle Plots:空间回收冰柱图
IEEE引用格式:H. Van De Wetering, N. Klaassen, and M. Burch, “Space-Reclaiming Icicle Plots,” IEEE Pacific Vis. Symp., vol. 2020-June, pp. 121–130, 2020, doi: 10.1109/PacificVis48177.2020.4908.
文献内容主要内容提出了空间回收冰柱图,在所有层次结构级别上回收空白空间,以提高层次结构元素的可见性
背景层次结构可视化通常在空间效率和层次结构描绘上存在一个权衡,高空间效率的层次结构无法提供有关结构的清晰视图,而保持结构化的则空间效率低
设计符合设计原则
从上到下的布局 从根到底部的视觉跟踪简单而直观
堆叠原理 堆叠结构清楚反应父子关系
结构清晰 轻松了解分支,深度和子层次结构大小
空间效率高 使用百分比参数回收丢失的空间
无重叠
子层次可选择
主要设计思想冰柱图子树垂直结束时,叶下垂直空间不能回收,形成损失空间,因此引入空间回收参数,同时,允许用户交互式调整
核心算法
等要用冰柱图相关内容时再 ...

Uncertainty Treemaps:可视化数据不确定性
IEEE引用格式:M. Sondag, W. Meulemans, C. Schulz, K. Verbeek, D. Weiskopf, and B. Speckmann, “Uncertainty Treemaps,” IEEE Pacific Vis. Symp., vol. 2020-June, pp. 111–120, 2020, doi: 10.1109/PacificVis48177.2020.7614.
文献内容主要内容研究了如何在Treemap中可视化分层数据和其相关的不确定性
提出了两个相互矛盾的关键要求
视觉聚合:矩框大小需要和值匹配
用区域编码不确定度:用相同视觉变量对不确定度编码,方便与数据的比较
通过使用不确定性遮罩在数据相同的空间可视化不确定性,同时满足两个要求,维持了Treemap的严格递归性质
还提出了一种遮盖的质量度量,用于指导Treemaps的布局算法修改
背景数值数据通常会有与每个数据值相关的不确定性,支持对复杂数据类型和不确定数据同时可视化的技术很少
实验数据集
coffee:1994年至2014年每个国家/地区的咖啡平均进口量以及相 ...
TreeEvo:祖先的特征是如何影响几代人的家谱的
IEEE引用格式:S. Fu, H. Dong, W. Cui, J. Zhao, and H. Qu, “How Do Ancestral Traits Shape Family Trees over Generations?,” IEEE Trans. Vis. Comput. Graph., vol. 24, no. 1, pp. 205–214, 2018, doi: 10.1109/TVCG.2017.2744080.
文献内容主要内容提出了一项设计研究,研究探讨了后代的生活史特征,男性创始人社会经济地位与家谱结构之间的关系
描述人口统计学领域的任务,帮助专家确定位置结构特征
设计和开发了可视化分析系统TreeEvo,用于假设生成和关联的验证
背景两代分析在研究和评估过程中比较简单,但是扩展到多代过程极具挑战性
人们对于多代人的社会经济和人口发展过程的先验知识有限,而错误的假设会在研究设计和统计估计中引入偏差,因此亟需视觉分析工具,基于新可用数据来生成和验证/拒绝假设
社会科学中大多数统计工具(SPSS,STATA,R)在可视化分析中受限(图形选项有限,需要高级 ...
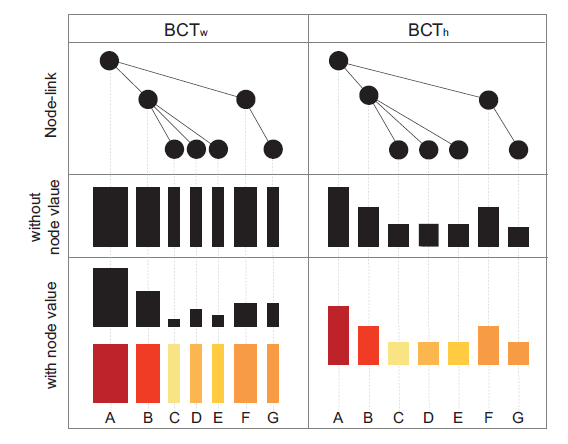
BarcodeTree:多层次结构的可伸缩比较
IEEE引用格式:G. Li et al., “BarcodeTree: Scalable Comparison of Multiple Hierarchies,” IEEE Trans. Vis. Comput. Graph., vol. 26, no. 1, pp. 1022–1032, 2020, doi: 10.1109/TVCG.2019.2934535.
摘要本文提出了一种新的可视化技术BarcodeTree(BCT),用于比较多棵树的拓扑结构和节点属性值。BCT可以同时提供100个浅层且稳定的树的概览,而不需要聚合单个节点。每个BCT使用类似于条形码的样式在单行中显示,允许树垂直堆叠,匹配节点水平排列,以方便比较并保持空间效率。作者设计了一些视觉线索和交互技术来帮助用户理解树的拓扑结构和比较树。在两种BCT与icicle plots的比较实验中,结果表明BCT降低了不同树之间的垂直距离,使树之间的比较更加直观。本文还提供了两个案例研究,涉及数百棵树的数据集,以演示BCT的效用。
文章简介数据集有时由许多相似的树(不同地方的图书馆)或随着时间变化的单个树组成(一个网站的 ...

ShapeWordle:阿基米德螺旋感知形状生成词云
IEEE引用格式:Y. Wang et al., “ShapeWordle: Tailoring Wordles using Shape-aware Archimedean Spirals,” IEEE Trans. Vis. Comput. Graph., vol. 26, no. 1, pp. 991–1000, 2020, doi: 10.1109/TVCG.2019.2934783.
摘要本文提出了一种新技术ShapeWordle,可以创建形状为界的文字,将文字变成给定的形状。为了在形状内指导单词的放置,扩展了传统的阿基米德螺旋,通过使用形状的距离场以差分的方式来表示螺旋,使其具有形状感知能力。为了处理非凸形状,本文引入了一种多中心Wordle布局方法,该方法将形状分割成可感知形状的螺旋部分,以自适应地填充空间并生成单词位置。此外,还提供了一组编辑交互,以方便创建语义上有意义的文字,最后提供了三个评价:比较本文结果和最先进的技术WordArt,14个用户的案例研究,以及一个展示技术覆盖范围的画廊
文章简介词云能够简单而有效地以引人入胜的方式来传达文本的概述,单词的大小表示了 ...
React学习记录:更强大的评论系统
我们来继续优化之前写的评论系统
功能实现CheckList
聚焦功能 组件参数验证 用户名记录 评论记录 发布时间显示 评论删除 代码块引入
聚焦功能首先给评论系统增加一个聚焦功能,具体是,当页面加载完毕之后,会自动聚焦到评论框
React.js通过ref来获取已经挂载的元素的DOM节点
我们在textarea中使用ref,ref是一个函数,当元素在页面上挂载完毕的时候,React.js 就会调用这个函数,并且把这个挂载以后的 DOM节点传给这个函数,之后我们就可以通过this.(元素名)来获取这个DOM元素
1234<textarea ...

从零开始的算法竞赛入门教程:贪心策略中的等值性
前言USACO Training 1.3的题目中出现了两题涉及到贪心思想,思路都比较简单,但是贪心策略呢,还是蛮难的一个东西,本文主要稍微介绍一下贪心中的一个比较重要的思想:等值性,当然还有一些题目会涉及等价性,但是通过转化还是会变成一个等值性的问题,我尽量挑选一些比较简单的题目阐释一下什么是等值性,以及这个性质在解题过程中一般会有什么用
题意[Mixing Milk]
给出牛奶制造公司每日的牛奶需求,以及每个农民的可提供的牛奶量和每加仑的价格,计算牛奶制造公司所要付出钱的最小值
解题思路拿到这个题,可能非常容易得到思路,将牛奶价格从低到高排序,依次购买
原理呢,就是等值性,所有牛奶都是一加仑一加仑出售的,如果买了价格高的一加仑,为何不用价格低的一加仑去替代呢,可能对贪心有所涉猎的同学会知道,这还有一个解释,就是等值性符合贪心的法则,局部最优解导向全局最优解
那如果每个农民的牛奶是盒装的,每个农民的包装盒大小不一,必须整盒购买,那这个时候还能采用这种贪心策略么,肯定就不行了,因为不具备等值性的情况下这种贪心策略无法保证无后效性,子问题的决策影响了全局最优解,举个极端的例子,你买最便宜的 ...


