TreeEvo:祖先的特征是如何影响几代人的家谱的
IEEE引用格式:S. Fu, H. Dong, W. Cui, J. Zhao, and H. Qu, “How Do Ancestral Traits Shape Family Trees over Generations?,” IEEE Trans. Vis. Comput. Graph., vol. 24, no. 1, pp. 205–214, 2018, doi: 10.1109/TVCG.2017.2744080.
文献内容
主要内容
提出了一项设计研究,研究探讨了后代的生活史特征,男性创始人社会经济地位与家谱结构之间的关系
- 描述人口统计学领域的任务,帮助专家确定位置结构特征
- 设计和开发了可视化分析系统TreeEvo,用于假设生成和关联的验证
背景
两代分析在研究和评估过程中比较简单,但是扩展到多代过程极具挑战性
- 人们对于多代人的社会经济和人口发展过程的先验知识有限,而错误的假设会在研究设计和统计估计中引入偏差,因此亟需视觉分析工具,基于新可用数据来生成和验证/拒绝假设
- 社会科学中大多数统计工具(SPSS,STATA,R)在可视化分析中受限(图形选项有限,需要高级编程技能),阻碍专家理解和处理分层数据结构
- 已有工具很少利用多代数据以及整个家谱集合中的结构信息来帮助发现重要信息
项目信息
专家方面
六位领域专家
- 一位人口统计专家 (本文共同作者)
- 一名教授 (历史人口和社会学领域) 和四名研究生
设计分三阶段,每个阶段包括所有专家一次正式面谈和内部专家的几次非正式面谈
- 确定多代分析中的重要研究问题并得出可视化的分析任务
- 根据专家的反馈对TreeEvo进行迭代开发
- 组织与不同专家的访谈,评估TreeEvo的有效性和实用性
数据集
CMGPD-LN
根据清朝(1644-1912)政府在1749年至1909年间在中国辽宁省编制的三年期户口簿抄录的。该数据集包含超过260万个人的150万条记录
确定领域研究问题
先简单可视化树集合,在集合面板用MDS布局显示族树集合(a),每个点代表一棵树,并且两个点彼此靠近意味着两个家族在位置,人口和世代数三个方面相似。 借助过滤(b),专家们可以选择感兴趣的家谱。选择族后,将显示族树的详细信息(c)

在早期模型中专家提出了一些原型无法回答的问题,比如家族树结构和男性创始人特征之间的关系
分析工作流程
重心放在仅由一个男性祖先和他的男性后代组成的家谱上
家谱的倾向与男性创始人的个人特征之间存在关联
世代数,男性成员数和倾斜度
倾斜度测量方法是专家新定义的
采用了Multinomial Logit Model(MLM)
专家采用STATA来运行MLM,对分析结果进行信息了解通常要生成统计图,但是STATA绘图选项效率低,绘图代价高
任务分析
分为两类:
结构识别
T1:通过深度或世代数来组织整个家庭树的收集
T2:通过结构特征汇总家庭树
T3:详细介绍家庭树的结构关联分析
T4:基于结构特征的灵活分区家庭树
T5:统计多变量分析与MLM的集成
TREEEVO
整体结构
采用桑基图(Sankey),为了支持针对增长和连续性的数据集的探索 (T1)
但是传统的Sankey图设计存在两种限制
- 由Sankey节点表示的元素处于聚合状态,丢失了许多细节,比如家谱的结构分布 (T2不满足)
- 传统Sankey图要求事先重新定义这些节点,很难按照要求灵活划分和选择具有各种结构特征的树集合 (T4不满足)
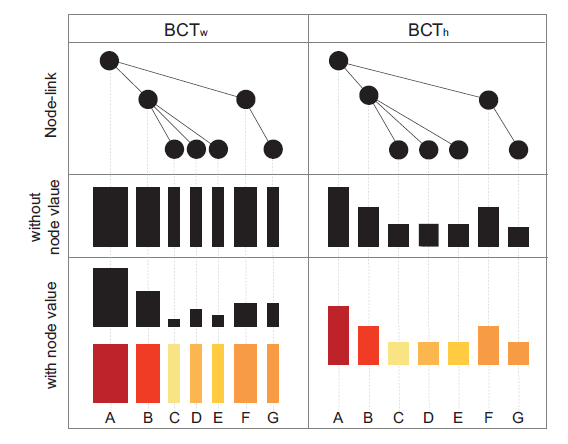
为了解决限制,重新设计了Sankey节点 (灵感来源于Monroe et al)
- 将每个家谱树概括成一条像素线 (图a)
- 将每条像素线的颜色编码 (图b)
- 可以根据结构特征对紧密对齐的像素线进行排序 (图c)
这样专家能根据结构树来了解家族树集合的分布 (T2)
并且根据具有灵活性的各种结构特征来划分分区树集合 (T4)
显示细节
当用户选择一个或多个Sankey节点时,显示详细信息,每个Sankey节点的详细组成都会在详细信息面板(T3)中以空格填充的形式显示
Nmap来计算空间填充布局
使用MLM进行分析 (T5)
阅读体会
这篇文章可视系统部分基本上就是对Sankey图的一个对于特定使用情况的优化和内容补充,用行来表示相同深度的家族树集(分三组:蓝-左倾斜,白-倾斜,红-右倾斜),节点对应不同家族树,而对于家族树的结构部分用矩形部分来补充(颜色:倾斜度,区域大小:数量),只有区域足够大才能显示族树的节点链接结构
这篇基本的研究思路就是和domain experts一起合作,对设计原型进行迭代,确定任务-初步模型-得到反馈(使用中什么问题没能回答)-迭代更新-使用反馈
一些缺陷也比较显然,比如这个设计只能处理深度比较小的情况,深度大的话,在矩形区域中很难显示,然后这个对于倾斜度单分组的设计过于specific,当然对于这个研究假设是够的,如果往多条件分组上考虑的话可以怎么做呢?(暂时没想到好的处理方法,先降维?或者做三维的类似桑基图的东西?)
![支付宝]() 支付宝
支付宝