将迁移学习应用于VQA
文章简介
VQA的方法依赖于大规模的图像数据集、问题和回答三元组,训练一个分类器,将图像和问题作为输入,然后生成一个答案,尽管最近取得了显著的进展,但这个框架有一个关键的局限性,即数据集中的图像、问题和回答三元组是学习视觉概念的唯一来源,这种缺陷可能会导致可扩展性的缺乏,因为标注人员可能会在质量控制有限的情况下人为地收集三元组,并且在视觉概念上多样性较弱
人类回答问题则是基于视觉概念的,视觉概念来自多个来源,比如书,图片,视频或是个人经验,但这些不一定和目标问题相关,机器也有很多可扩展的学习视觉概念的资源:图像类标签,边框和图像描述,那么能否学习没有标注的视觉概念并将其迁移到VQA系统中呢?
为了解决这个问题,作者引入了一个包含词汇表之外答案的VQA问题,如图所示

文章研究了在没有问题的情况下对视觉概念的学习,以及如何将学习到的视觉概念转化为VQA模型,文章提出的迁移学习框架有助于在词汇量不足的VQA中进行泛化
文章的主要贡献如下:
- 提出了一种基于任务条件视觉分类器的视觉问题回答迁移学习算法
- 提出了一种非监督任务发现技术,用于学习任务条件视觉分类器,无需明确的任务注释
- 实验表明,该方法通过不带问题标注的可视化数据集的知识迁移来处理词汇表以外的答案
相关工作
标准的VQA评估中训练集和测试集的分布是相同的,这种设置很容易遭到利用偏见(bias)的模型的攻击,因此有了许多替代的评估方式,一种方法是通过平衡个别问题的答案或有意地为训练集和测试集提供不同的偏差来减少观察到的偏差,另一种方法是构建组合,比如VQA-CP,作者研究的则是迁移学习,即从外部视觉数据中学习词汇之外的答案
为了更好地泛化,VQA训练通常使用外部数据,在ImageNet上预训练的卷积神经网络是多种VQA模型中被广泛使用的标准,而目标检测则是在Visual Genome数据集预训练,问题编码器的参数初始化经常使用预训练的语言模型,如词嵌入或句嵌入,也有一些研究利用欧冠知识库或者外部视觉算法的信息检索作为VQA模型的额外输入
从外部数据中迁移学习以应对词汇量之外的词汇在VQA中很少被研究,但在对象字幕中被积极研究,比如将图像字幕任务分解为视觉分类和语言建模,利用未配对的视觉和语言数据作为附加资源,分别训练视觉分类器和语言模型,有的方法结合了指针网络,并学习指向候选词的索引,其中候选词由经过外部视觉数据训练的多标签分类器或目标检测器检测,但是这些做法在VQA上不适用,因为它们专注于没有任务说明的目标词,而VQA需要任务条件视觉识别
作者的研究和零样本学习相近,都是在分类时考虑词汇外的答案,但是零样本学习旨在识别训练中看不到的物体或者类,因为目标是将其推广到完全不可见的类,所以在训练过程中严禁接触到零样本内容,而作者的目的是利用外部数据集中可用的类标签
迁移学习框架
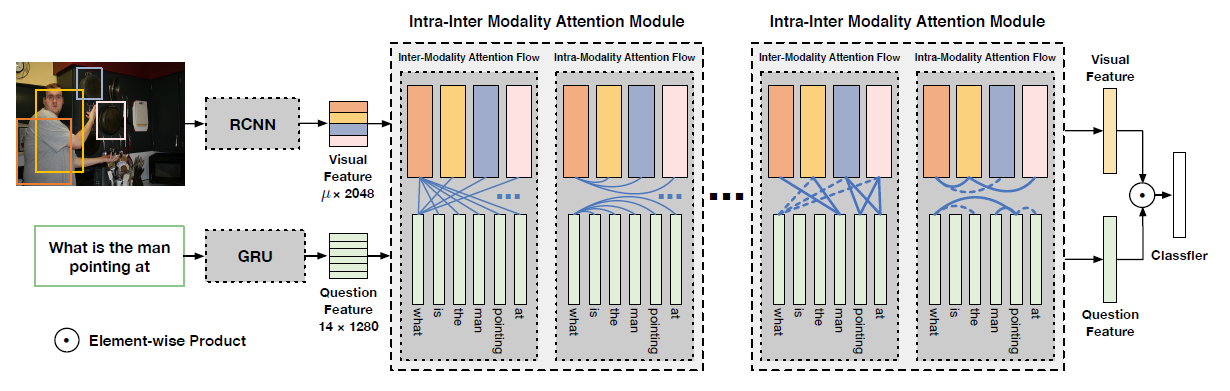
这篇文章工作的主要目标是在VQA中处理词汇表之外的答案,通过学习off-the-shelf视觉数据集中的视觉概念,将这些概念迁移到VQA中来回答问题,VQA可以被看做是一个任务条件分类问题,作者定义了一个任务条件视觉分类器,利用视觉输入和任务规范产生答案,作为学习和迁移用的视觉概念,整体框架如图所示
任务条件视觉分类器
任务条件视觉分类器是一个以视觉特征和任务特征作为输入并产生答案标签概率分布的函数
在迁移学习中,任务条件视觉分类器使用现成的视觉数据集Visual Genome预训练,然后迁移到VQA,该阶段允许任务条件视觉分类器通过学习任务特征来处理不同的视觉识别任务
预训练
学习任务的条件视觉分类器可以自然地表述为最大化以下期望对数似然
针对VQA的迁移学习
VQA模型包含任务条件视觉分类器$p_{\theta}(a|v,\tau)$,预训练的视觉概念通过共享学习参数$\theta$迁移到VQA,学习VQA模型本质上就是学习$p_{\theta}(a|v,\tau)$中的$v$和$\tau$
—— 弱监督任务回归
利用预先训练好的任务条件视觉分类器进行问题q指定的视觉识别,推断出最优的任务特征,这需要引入一个学习问题-任务回归-来生成一个encoder以正确预测任务特征,最小化误差要求对任务的额外监督,因此作者用VQA数据做弱监督,优化了间接损失
鼓励$\tau_q^*$和$\tau_{\eta_{vqa}}(q)$尽量相似
—— 词汇表之外的回答
在固定好预训练的任务条件视觉分类器$p_\theta(a|v,\tau)$之后,通过改变输入的形式来训练VQA模型,这种方式允许模型学习从问题中推断视觉识别任务,而不需要所有可能答案的数据,一旦推断出任务特征$\tau$,任务条件视觉分类器$p_\theta(a|v,\tau)$就能够回答预训练的视觉概念,涵盖词汇表外的回答
—— 视觉特征匹配
为了能够重复使用预训练的视觉分类器而不需要微调,视觉特征v的语义不应该通过学习VQA数据集而改变,这一点在最近的VQA模型中得到了实现,这些模型不微调预先训练好的视觉特征提取器,而是在提取的特征图上专注于学习注意力机制,而在文章中,作者只是简单地对预训练和VQA采用相同的视觉特征提取器
无监督任务发现
使用现成的可视化数据集学习任务条件视觉分类器并不容易,因为缺少对任务规范的标注,这对学习一个任务规范向量$\tau$的编码器来说是必需的,为了解决这一问题,作者提出了无监督任务发现,即利用语言知识资源从任务分布模型中抽取任务规范
利用语言知识来源
一个问题给出的视觉识别任务通常定义一个从视觉输入到一组可能的视觉概念(即一组单词)的映射,比如”那个女人手上拿着什么”在图片中定义了一个视觉识别任务”找到被手持的物品”,这是一个到词组{球,球拍,水杯,…}的分类,因此可以将任务视为单词组来建模模型的分布,使用语言知识源进行无监督任务发现的主要原因是语言知识源中经常可以访问到词汇组,作者考虑了两个语言知识来源:带有视觉数据的视觉描述和结构化词汇数据库WordNet
视觉描述
作者采用Visual Genome作为现成视觉数据集,定义了一个数据分布$P_v(a,I,b,d)$,这个数据集被设计为描述中明确提及答案a,因此答案和描述之间的关系是清晰的
作者将视觉描述中的答案替换为一个特殊词<空白>来定义任务规范$t_d$,该词正式表示为$t_d=\rho(d,a)$,$\rho(d,a)$为生成空白描述的函数,$t_d$的下标表示一个基于视觉描述提取的任务规范,任务规范为
对于任务规范使用空白描述的主要原因是定义一组候选词是有效的。例如,一个空白的描述”一个人持有_____”,将空白的候选词限制为一组可以持有的对象。因此,可以使用空白描述来隐式地确定表示视觉识别任务的单词组
WordNet
WordNet是一个词汇数据库,他用synset消歧词实体的有向无环图表示,一个简单的WordNet的子图如图所示
基于WordNet和可视化数据$(a,i,b,d)$的任务规范$t_w$采样过程如框架图中(b)WordNet所示,在WordNet中,作者将任务规范$t_w$定义为节点的synset,节点是多个单词的共同祖先,因为共享共同祖先的一组单词构造了一个单词组,而单词组还可以定义一个视觉识别任务
该过程的主要思想是将基于答案$p(t_w|a)$的任务分布建模为答案所属的可能的词组上的均匀分布,其中任务规范$t_w$是词组中词的共同祖先,建立分布$p(t_w|a)$分为两个步骤:1)构造一个词组表,该表将任务规范映射到词组;2)构造一个反词组表,它将回答词映射到一组任务规范,反词组表用于检索回答a的一组可能的任务规范,分布$p(t_w|a)$是该集合中任务规范的均匀分布,表示为
在WordNet中选择节点的一个synset作为任务规范$t_w$,并将其映射到与其所有后代对应的一组单词(一个单词组),从而构造单词组表。任何词组都可以定义,无论其在WordNet层次结构的级别和其成员的词性;最大的词组包含所有的词;WordNet及其任务规范对应于WordNet的根。反向词组表的构造方式类似于词组表的反向索引,但是映射的范围不是一组索引,而是一组任务规范
实验结果
词汇表之外的回答
弱监督任务发现的结果
![支付宝]() 支付宝
支付宝