VQA:数据集,算法和未来挑战 [综述]
VQA(Visual Question Answering)是一个计算机视觉task,给定一个图片相关的问题和对应的图片,通过程序推断出答案
要求解决的问题是任意的,并且包含了诸多计算机视觉当中的子问题,比如
- 目标识别 (图中的物体是什么)
- 目标检测 (图中有猫么)
- 属性分类 (图中的猫是什么颜色的)
- 场景分类 (图中的天气是晴天么)
- 计数 (图中有几只猫)
当然除了这些,还有更多复杂的问题,比如目标的空间关系问题 (在沙发和猫之间的物体是什么),常识推理问题 (图中的女孩为什么哭)
这是一篇2017年发表在Computer Vision and Image Understanding关于VQA的综述,文章内容包含以下几块
- VQA与一些视觉和语言问题的对比
- VQA当前可用的数据集以及优缺点
- 讨论VQA的评价指标
- 分析VQA已有的算法
- 讨论VQA未来的发展
VQA与其它视觉与语言任务的对比
(这部分大致是我对这个章节的翻译,了解一下背景)
VQA的最终目标是从图片中获取问题相关的信息,根据问题,任务的范围可以从微小细节的检测到整张图片场景特征的推理,其它从图片中提取信息的计算机视觉问题,和VQA相比,范围和通用性都是有限的
目标识别,动作识别,场景分类都可以被归为图片分类问题,目前最好的方法无一例外都是训练CNN,将图片划归到特定的语义类别,其中表现最佳的目标识别算法已经能够和人类平分秋色。然而目标识别只要求将图片中的显性目标分类,而并不要求了解它的空间位置或是在更大场景中扮演的角色。目标检测包含语义分割,目前最佳的目标检测算法均使用Deep CNN。语义分割通过将每个像素点分类来完成task。实例分割通过同一语义类中不同实例之间的差异进一步区分。
语义分割和示例分割是计算机视觉领域的重要问题,是对目标检测和识别的概括,但是它们对图像整体的理解是不够充分的,其面临的主要问题之一是标签的模糊性,语义标签可以由不同解释,取决于不同的任务。此外,仅这些方法无法理解对象在更大上下文中的作用,比如bag不会告诉我们这个像素是否由人携带,而将像素标记为person并不会告诉这个人是坐着,跑着或是在滑板。而VQA则要求系统回答关于图像的任意问题,这需要对对象之间的关系和整个场景推理,而适当的标签则由问题指定。
除了VQA,近期还有一些工作也结合了视觉和语言,其中有较多人研究的是图像字幕,算法的目的是为图片产生自然的描述,图像字幕是一个非常广泛的任务,包括描述复杂属性和对象的关系来从细节上描述图片。
然而视频字幕存在一些问题,对字幕的评估就是一个特殊的挑战,理想的方法是让人类评审进行评估,但是这种方法缓慢而昂贵。因此,出现了多种自动评估方案。最为广泛使用的评价系统有BLEU,ROUGE,METEOR以及CIDEr,除了CIDEr是从图片描述评分发展而来之外,其它几种都是从机器翻译评价发展而来的。这些方法都存在局限性,比如最为广泛使用的方法BLEU,对于句子结构和语义变化巨大的句子具有相同的评分。在一些研究中,BLEU将生成字幕排在人类字幕之上,但是当人工判断的时候,只有少数人认为字幕与人类字幕具有相同好的效果。而虽然CIDEr和METEOR,和人类评审具有较高的一致性,但它们仍然经常将自动生成的字幕排名高于人类字幕。
评估字幕具有挑战性的一个原因是给定图像可以有许多合理的字幕,一些是非常特殊的,而一些是一般的。然而,字幕系统如果仅生成描述图片的通用字幕往往可以得到很高的评分,比如”一个人在街上走”和”街上有几辆车”等可以适用于大量图片的通用字幕。事实上,建立一个简单的系统,用最近邻算法返回具有最相似视觉特征的图片的字幕,使用自动评估就能得到较高的分数。
密集图像字幕 (Dense image captioning, DenseCap) 通过使用与小而突出的图像区域相关的简短视觉描述密集地注释图像,避免了一般的字幕问题,比如一个DenseCap系统可以输出”一个穿黑衬衫的人”、”大绿树”和”楼顶”,每个描述都有一个边界框,系统可以为丰富的场景生成大量的这些描述。尽管这些描述中有许多是简短的,但自动评估它们的质量仍然是困难的。DenseCap还可以忽略场景中对象之间的重要关系,只为每个区域生成独立的描述。字幕和DenseCap也是任务不可知的,系统不需要对图像进行深度理解。
字幕系统是可以自动选择图像的粒度级别的,这与VQA不同,VQA的粒度级别是根据问题的性质来决定的,比如”这是什么季节”需要了解整个场景,但是”穿白裙子的女孩后面的狗是什么颜色的”需要注意场景的具体细节。此外,许多类型的问题都有明确的答案,这使得VQA比字幕更适合于自动化的评估指标。某些问题类型可能仍然存在歧义,但对于许多问题,VQA算法产生的答案可以通过与基本真实答案的一对一匹配来评估
VQA的数据集
DAQUAR
第一个主要的VQA数据集,最小的数据集,包含6795张训练数据和5673张测试数据,所有图像来自于数据集NYU-DepthV2 Dataset。数据集质量较差,一些图像杂乱无章,分辨率低,并且问题和回答有明显的语法错误
COCO-QA
这个数据集是通过NLP算法对COCO数据集生成的,78736训练数据,38948测试数据,数据集中问题包括目标提问(69.84%),颜色提问(16.59%),计数(7.47%)和位置提问(6.10%),所有问题的答案都是单个单词。数据集最大的缺点在于所有的问答都是通过NLP算法生成的,因此句式单一且存在语法问题,此外只包含四种类型的问题
The VQA Dataset
该数据集的图片包括COCO数据集和抽象卡通图片,且该数据集有两个子集,COCO-VQA和SYNTH-VQA
COCO-VQA对每张图片有三个问题和对于每个问题的十个回答,问题是人工提出的,回答由10个不同的人完成,数据集包含248349训练数据,121512验证数据和244302测试数据
SYNTH-VQA包含50000张合成场景,涉及100种目标,30种不同的动物模型和20种人类卡通模型,同样这个数据集对每张图片有三个问题和对于每个问题的十个回答。合成场景的目的是为了消除biases,比如原先在真实场景中,街道上一般都是狗,而不会是斑马
因为多样性和大小,COCO-VQA被广泛使用,但是这个数据集中也有很多问题,比如有些问题不存在简单客观的答案,而有些问题可以不需要看图片就能够回答,比如”图中树的颜色”,答案基本是”绿色”,还有yes/no的问题有六成是yes,这些都是这个数据集的biases
FM-IQA
这个数据集的图片也来自COCO,它的提问和回答起初是中文,然后被翻译成英文,回答可以是一整个句子。数据集的提供者建议采用人工判定,即判断回答是来自机器还是人类
Visual Genome
数据集的图片来自COCO和YFCC100M,包含108249张图片和170万QA pair,目前最大的数据集(2016.10)。数据集的提问包含What, Where, How, When, Who, Why。数据集要求提问者尽量从图片整体提问,比如”图片中有几只斑马”以及”图片当中是什么天气”,这能够很好的消除提问种类的biases。同时这个数据集当中,没有yes/no类型的问题
Visual7W
Visual7W是Visual Genome数据集的子集,包含47300张图片,问题种类包含What, Where, How, When, Who, Why, Which。这个数据集通过多选来评估,每个问题包含四个选项
SHAPES
SHAPES是一个特殊的数据集,包含各种排列,形状和颜色,问题包含属性,位置和形状,数据集包含244个独特的问题,答案均为yes/no,SHAPES只是作为一个附加评估,而不能取代真实图片数据集,若一个算法在其它训练集上都表现良好而在SHAPES上表现不好,说明其分析图片的方式是有限的
VQA的评价指标
Simple Accuracy
在多选问题中被经常被用于评估,优点是能够简单地评价和说明,并且在数量少且答案唯一的数据集上表现良好。缺点是无法区别惩罚,在开放性的QA当中无法指导训练,比如答案是dogs,但是dog很明显是比zebra要更优的,尤其是以句子为答案的问题,更难以评估
Modi ed WUPS
WUPS是通过语义上的差别来衡量答案的好坏,通过语法树来实现。优先是对简单的变化和小错误有更大的包容度,不要求完全匹配,并且可以通过脚本简单评估。缺点是对于结构相近但是意思完全不同的单词具有高评分,比如”白色”和”黑色”。并且不能用于句子或者语法答案
Consensus Metric
同一问题的相同答案将会获得高分,如果有一致性数据可以简单地评估,但是允许问题存在两个答案,同时真实数据很难收集
Manual Evaluation
优点是短语和句子同样可以评估,但是人工评价费时费力,且存在主观判断
VQA算法
VQA的算法一般分为三个步骤
- 图像特征提取
- 问题特征提取
- 结合两者特征来产生答案
图像特征提取部分常用的有VGGNet,ResNet,GoogLeNet,问题特征提取部分常用的有BOW,LSTM,GRU以及skip thought vectors,而最后结合两者特征通常被视为分类问题来处理,常见处理方法分为以下几种
- 用简单的方法将特征结合起来,比如特征矩阵连接,矩阵元素点乘或相加,然后扔进分类器或者神经网络
- 用双线性池或者相关方案将特征结合然后扔进神经网络
- 使用分类器对问题特征分类,以计算空间注意力图,或是采用注意力机制获得图像的自适应局部特征图
- 采用贝叶斯模型来计算question-image-answer分布的潜在关系
- 用问题将VQA任务划分为多个子任务
Baseline Models
基线模型对应处理方法1,简单方法结合特征,矩阵连接,矩阵元素点乘或相加等
[1]中用BOW表示问题,GoogLeNet提取图片特征,将特征矩阵连接之后放入逻辑分类器
(BOW(Bag of words)是词袋分析法,对文本,忽略其词序和语法,表达为词数量向量)
[1] B. Zhou, Y. Tian, S. Sukhbaatar, A. Szlam, and R. Fergus, “Simple baseline for visual question answering,” arXiv preprint arXiv:1512.02167, 2015.
[2]中用skip-thought提取问题特征,ResNet-152提取图片特征,用包含两个hidden layer的MLP模型做特征结合,结果是MLP模型过拟合
(skip-thought:用一个编码器对当前句进行建模,用两个独立的自回归解码器分别建模前一个句子和后一个句子)
[2] K. Kae and C. Kanan, \Answer-type prediction for visual question answering,” in The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016
同时,有很多研究采用LSTM来处理language
[3]用LSTM处理one-hot encoding sentence来表示问题特征,GoogLeNet来表示图片特征,然后对经过CNN的图片特征进行降维以匹配问题特征,取两者的 Hadamard product (其实就是矩阵点积),用两层的MLP处理
(one-hot encoding:独热编码,又称为一位有效编码,使用N位状态寄存器来对N个状态进行编码,每个状态都有它独立的寄存器位,并且在任意时候,其中只有一位有效。对于每一个特征,如果它有m个可能值,那么经过独热编码后,就变成了m个二元特征。并且,这些特征互斥,每次只有一个激活。因此,数据会变成稀疏的。解决了分类器不好处理属性编码的问题,起到扩充了特征的作用)
[3] S. Antol, A. Agrawal, J. Lu, M. Mitchell, D. Batra, C. L. Zitnick, and D. Parikh, \VQA: Visual question answering,” in The IEEE International Conference on Computer Vision (ICCV), 2015
在[4]中,每个单词被嵌入CNN特征后输入到LSTM,直到问题结束,之后的CNN特征用于产生答案
[4] M. Malinowski, M. Rohrbach, and M. Fritz, \Ask your neurons: A neural-based approach to answering questions about images,” in The IEEE International Conference on Computer Vision (ICCV), 2015.
[5]中的工作则是将CNN特征作为第一个词和最后一个词输入到LSTM中,随后用softmax classi er预测答案
[5] M. Ren, R. Kiros, and R. Zemel, \Exploring models and data for image question answering,” in Advances in Neural Information Processing Systems (NIPS), 2015
[6]用了两个LSTM,和[5]相比,它只将CNN特征作为最后一个词输入到LSTM中,然后用另一个LSTM取代了分类器的工作
[6] H. Gao, J. Mao, J. Zhou, Z. Huang, L. Wang, and W. Xu, \Are you talking to a machine? Dataset and methods for multilingual image question answering,” in Advances in Neural Information Processing Systems (NIPS), 2015.
Bayesian and Question-Aware Models
VQA需要图像和问题之间的推断策略和关系建模,当问题和图片被特征化之后,对其共现性(co-occurrence)的建模对答案的推出大有帮助
[7]第一次提出VQA的贝叶斯框架,作者用语义分割标识出目标和其位置,随后训练贝叶斯模型对目标的空间关系进行建模,以此来衡量每个答案的可能性。然而其依赖于语义分割,因此效率低下
[7] M. Malinowski and M. Fritz, \A multi-world approach to question answering about realworld scenes based on uncertain input,” in Advances in Neural Information Processing Systems (NIPS), 2014.
[8]中先根据问题来预测答案,随后处理图像特征和问题特征,为此,使用了大量的二次判别分析
[8] K. Kae and C. Kanan, \Answer-type prediction for visual question answering,” in The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
Attention Based Models
只使用全局特征会致使目标相关区域模糊化,注意力机制则尝试去解决这个问题,这些模型学习去注意与输入空间最相关的区域。注意力机制的核心思想就是特定的视觉区域或者特定的单词比剩余的包含更多的有效信息。
注意力机制的引入通常有两种方式,一种方式是将图像均匀地划分为网格,每个网格代表图像的局部特征,此操作一般设置在最后一层卷积层之前,然后池化层将特征展开。随后由问题来确定每个网格之间的相关性

另一种方式是为图片生成bounding boxes,用CNN对这些boxes的内容编码,然后根据问题来决定这些boxes之间的关系
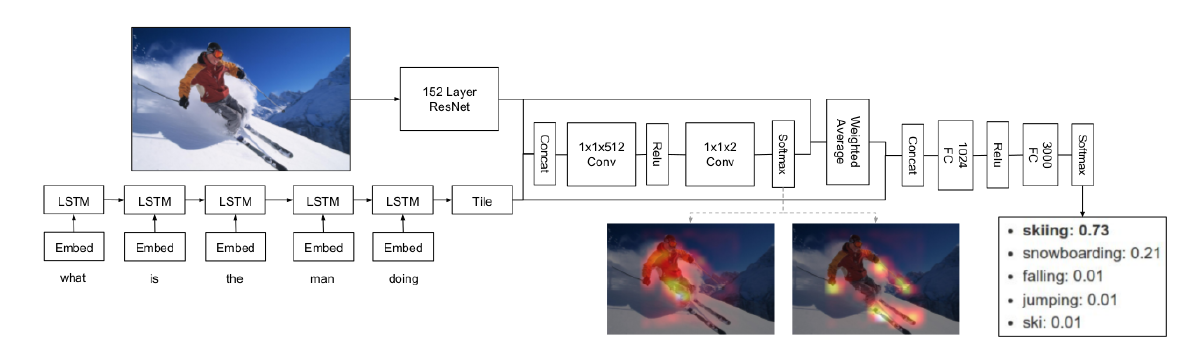
Focus Regions for VQA[9]用Edge Boxes生成bounding box region proposals,用CNN提取boxes中的特征,其VQA系统的输入包括CNN特征,问题特征和答案多选,系统为每个答案产生一个分数,将最高分作为最终的答案。分数通过各个区域加权平均计算,加权平均的权重通过全连接层学习CNN特征和问题特征的点积来得到
[9] K. J. Shih, S. Singh, and D. Hoiem, \Where to look: Focus regions for visual question answering,” in The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
Focused Dynamic Attention (FDA)[10]中,作者只使用和问题中目标相关的proposals,他们的VQA系统的输入为bounding boxes和其对应的目标标签,训练时,bounding boxes和目标标签通过COCO annotations得到,测试时,标签通过ResNet对bounding boxes分类得到。然后用word2vec来计算问题关键词和bounding boxes的一致性得分。得分高于0.5的bounding box被输入到LSTM中,同时采用另一个LSTM来表示问题,将两个LSTM的输出同时输入到全连接层中,最后用softmax classi er来预测
[10] I. Ilievski, S. Yan, and J. Feng, \A focused dynamic attention model for visual question
answering,” arXiv preprint arXiv:1604.01485, 2016.
Stacked Attention Network (SAN)[11]利用问题特征,CNN特征以及softmax激活函数来计算图像上的注意力分布,然后将其应用到CNN特征图中,使用加权和将空间特征位置集合起来,来生成强调特定空间区域的全局图像表示。然后这个特征向量和问题特征联合,通过softmax来产生答案。这个方法可以产生多个注意力层,使得系统可以处理多个目标之间的复杂关系
[11] Z. Yang, X. He, J. Gao, L. Deng, and A. J. Smola, \Stacked attention networks for image question answering,” in The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
Spatial Memory Network[12]中,通过评估图像块与问题中单个单词的相关性来产生空间注意力,这种word-guided注意力被用于预测注意分布,然后计算嵌入图像区域的视觉特征的加权和。文章研究了两种模型,在单跳模型中,整个问题的特征与加权视觉特征相结合来预测答案。在双跳模型中,视觉特征和问题特征的结合被循环回注意机制中,以重新确定注意分布
[12] H. Xu and K. Saenko, \Ask, attend and answer: Exploring question-guided spatial attention for visual question answering,” in European Conference on Computer Vision (ECCV), 2016.
modi ed Dynamic Memory Network (DMN)[13]中,采用了整合注意力,包含输入模块,情节记忆模块和答案模块,同样是采用CNN特征作为word输入到RNN当中的方法
[13] A. Kumar, O. Irsoy, J. Su, J. Bradbury, R. English, B. Pierce, P. Ondruska, I. Gulrajani, and R. Socher, \Ask me anything: Dynamic memory networks for natural language processing,” in International Conference on Machine Learning (ICML), 2016.
在Hierarchical Co-Attention model[14]中,主要贡献是将注意力机制同时运用在问题和图像上,图像的处理和SMN类似,问题的处理首先用了分级编码 (hierarchical encoding):在word level使用one-hot encoding,在phrase level使用bi- or tri-gram window size,在question level使用LSTM,通过分级,可以使用两种不同的注意力机制
[14] J. Lu, J. Yang, D. Batra, and D. Parikh, \Hierarchical question-image co-attention for visual question answering,” in Advances in Neural Information Processing Systems (NIPS), 2016.
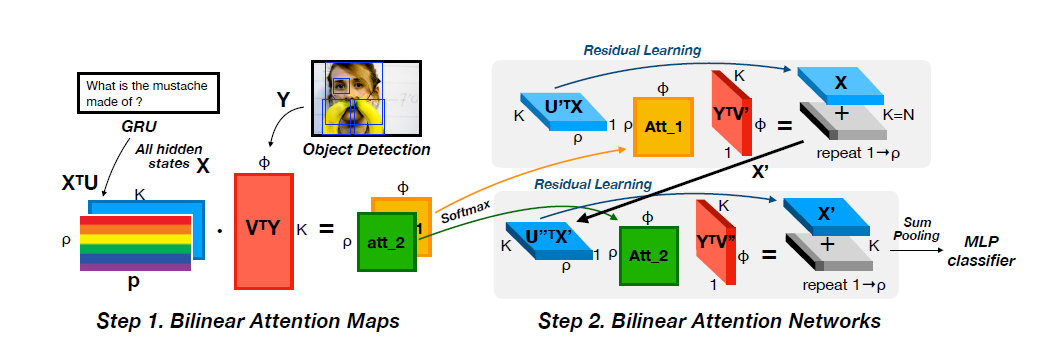
Bilinear Pooling Methods
VQA依赖于对图像和问题的联合分析,早期模型通常用简单方法将他们的特征结合起来,比如矩阵连接,矩阵元素积等,但是我们期待更复杂的方法去处理它们,比如矢量积。因此有了双线性池化方法。
[15]提出了Multimodal Compact Bilinear pooling(MCBP),其本质是在低维度条件下进行矢量积的近似。并将其应用在VQA,一共用到了两次MCBP模块,第一个MCBP融合了文本和图像的特征进而用来提取图像的attention,第二个MCBP将图像的attention特征与文本特征再一次融合,最终结果送入softmax分类器得到答案
[15] A. Fukui, D. H. Park, D. Yang, A. Rohrbach, T. Darrell, and M. Rohrbach, \Multimodal compact bilinear pooling for visual question answering and visual grounding,” in Conference on Empirical Methods on Natural Language Processing (EMNLP), 2016
[16]中进一步优化近似矢量积的开销,用Hadamard乘积和线性映射来实现近似双线性池化
[16] J.-H. Kim, K.-W. On, J. Kim, J.-W. Ha, and B.-T. Zhang, \Hadamard product for low-rank bilinear pooling,” arXiv preprint arXiv:1610.04325, 2016.
Compositional VQA Models
在VQA中,问题通常是分为多个步骤的,比如问题”马的左边是什么”首先要找到马,然后对它左边的物体命名。基于这种想法,目前有两种组合框架通过sub-step的方式来解决VQA问题,Neural Module Network (NMN)和Recurrent Answering Units (RAU)
NMN通过问题解析器将问题划分为sub-task,然后用sub-networks来分别解决,常用模块包含find,describe,transform,比如’What color is the tie’采用先find[tie],然后describe[color]的方案完成
而RAU不需要依赖于语言解析器,模型采用多个自循环的回答单元来解决VQA的sub-task,回答答案周期性排列,以注意力机制驱动
其它有价值的模型
引入知识库,先验知识可以帮助系统在特定问题上更好地回答;[17]在CNN的全连接层之前引入了Dynamic Parameter Prediction layer,这一层的参数通过RNN处理问题得到,这使得视觉特征在最终的分类步骤之前就能够和问题建立关系,这种做法可以看做是一种隐注意力机制;[18]采用Multimodal Residual Networks (MRN)来处理VQA,MRN改自ResNet,同时对视觉和问题特征进行残差映射,视觉和问题拥有各自的残差块,而在每个残差块之后,视觉信息被掺入了问题信息,作者尝试了多种残差块的处理方式
[17] H. Noh, P. H. Seo, and B. Han, \Image question answering using convolutional neural network with dynamic parameter prediction,” in The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
[18] J.-H. Kim, S.-W. Lee, D.-H. Kwak, M.-O. Heo, J. Kim, J.-W. Ha, and B.-T. Zhang, Multimodal residual learning for visual qa,” in Advances in Neural Information Pro-cessing Systems (NIPS), 2016.
何种方法模型表现更佳
ResNet的提取特征能力更佳,注意力机制有相比较好的效果,贝叶斯模型和组合模型对于正确率提升没有明显的帮助
讨论
VQA中的视觉和问题
相比于图片,当下VQA系统更依赖于问题,数据集中的bias对VQA的影响非常大。通过实验可以发现image-blind模型在正确率上甚至可以超过早期结合了问题和图片的模型。同时问题和答案之间也存在bias,比如相同意思的问题,VQA对不同的句式会产生不同的答案
之后要解决的问题就是减少数据集中答案和问题之间的bias,同时要求算法可以更充分地使用图片特征,而不是极大地依赖于问题特征
注意力机制在VQA中有多有用
很难说注意力在VQA中起到了多大的作用,有简化研究表明去除注意力机制会使模型的正确率下降,在COCO-VQA表现最好的模型也使用了注意力机制,然而有的未使用注意力机制的简单模型比采用了复杂注意力机制的模型表现更佳
注意力机制受到bias的影响,比如查询图片中是否存在窗帘(drapes),注意力可能会从图片底部开始寻找,最后锁定在床(bed),因为drapes在问题中通常和bedroom相关
bias的损害
数据集的bias影响了对VQA算法的评估,场景以及目标属性的问题具有很强的bias,而这类问题在COCO-VQA正确率的提升对整体正确率的提升有较大影响,而复杂的’Why’ and ‘Where’问题的正确率提升对整体正确率提升却影响甚微,这个情况可以通过对每种类型的问题分别评估来解决
二值问题是否充分
目前主要的争论是二值问题是否会导致问题复杂性的缺失
二值问题的优点是非常容易用于评估,如果bias能够得到控制,那么这类问题用于测试就完全没有问题
开放式 vs 多选
因为开放式多词回答是难以评估的,因此多选答案这种方式在多个数据集中被使用
然而多选题这种方式本质上是对任务的简化,它使得任务变成判断哪个答案是对的,而不是真正地去回答这个问题。比如将答案也作为特征进行训练,就能达到SOTA,但其实,这种方法只是学习了答案中的bias,作者提议所有的VQA系统都必须在不给定答案作为input的时候能够运作
未来VQA数据集的建议
- Future datasets need to be larger. (更大)
- Future datasets need to be less biased. (更少bias)
- Future datasets need more nuanced analysis for benchmarking. (问题种类更多更全面)
![支付宝]() 支付宝
支付宝